db <- foreign::read.spss(file=paste0(getwd(),
"/data/1186_Selects2019_CandidateSurvey_Data_v1.1.0.sav"),
use.value.labels = T,
to.data.frame = T)
sel <- db |>
dplyr::select(B12,T9a) |>
stats::na.omit() |>
dplyr::rename("budget"="B12", "party_list"="T9a") |>
plyr::mutate(budget=as.numeric(as.character(budget))) |>
plyr::mutate(party_list=as.factor(party_list))
# filter candidates with maximally a budget of 100'000
boxplot(sel$budget)(M)AN(C)OVA presentation
Learn what (M)AN(C)OVA is and how to run the analysis in R
2.2 Variance decomposition
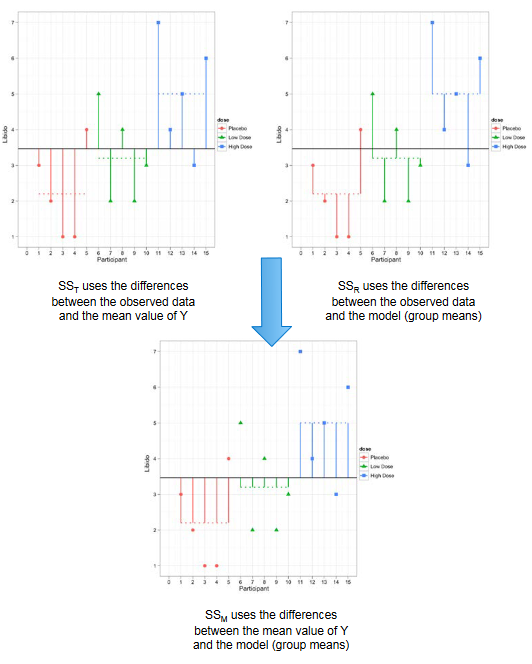
2.3 Total sum of squares (TSS)
The total amount of variation within our data is the difference between each observed data point (\(\hat{y}_{ij}\)) and the grand mean (\(\hat{y}_{Grand}\)). We then square these differences and add them together to give us the total sum of squares (TSS).
\[ TSS = \sum{(\hat{y}_{ij} - \hat{y}_{Grand})^2} \]

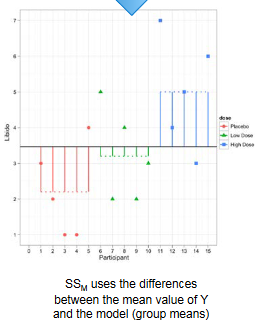
2.4 Model sum of squares (MSS)
The model sum of squares (MSS) requires us to calculate the differences between each participant’s predicted value (\(\hat{y}_j\)) and the grand mean (\(\hat{y}_{Grand}\)). It is the sum of the squared distances between what the model predicts for each data point (i.e., the dotted horizontal line for the group to which the data point belongs) and the overall mean of the data (the solid horizontal line).
\[ MSS = \sum{n_j(\hat{y}_j - \hat{y}_{Grand})^2} \]
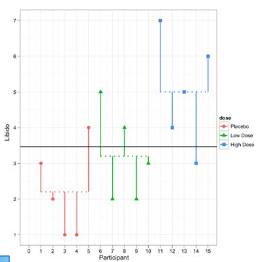
2.5 Residual sum of squares (SSE)
The final sum of squares is the residual sum of squares (SSE), which tells us how much of the variation cannot be explained by the model. The simplest way to calculate SSE is to subtract MSS from TSS. It is calculated by looking at the difference between the score obtained by a person and the mean of the group to which the person belongs.
\[ SSE = \sum{(y_{ij} - \hat{y}_i)^2} \]
5.1 Example
Let’s prepare data to investigate whether the campaigning budget varies significantly across parties:

6.1 Variance homogeneity
To assume that the variances are homogeneous, there should be no clear correlations between residuals and fitted values (the mean of each group) in the plot below.

Levene’s test is recommended since it is not very sensitive to deviations from normal distribution. If the p-value is less than the significance level of 0.05, it indicates that the variance across groups is statistically significant.
Levene's Test for Homogeneity of Variance (center = median: sel)
Df F value Pr(>F)
group 7 9.8826 3.696e-12 ***
1882
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1An alternative approach (e.g., the Welch one-way test) does not necessitate the use of equal variance assumptions (in R: oneway.test() and pairwise.t.test())
6.2 Normality
We can infer normality if all of the points lie roughly along this reference line.

Run Shapiro-Wilk test on the ANOVA residuals. If the p-value is <0.05, it suggests that there is evidence of normality violation.
Shapiro-Wilk normality test
data: aov_residuals
W = 0.53433, p-value < 2.2e-16The Kruskal-Wallis rank-sum test is a non-parametric alternative to one-way ANOVA that can be employed when the ANOVA assumptions are not met (in R: kruskal.test()).
8.1 Typology
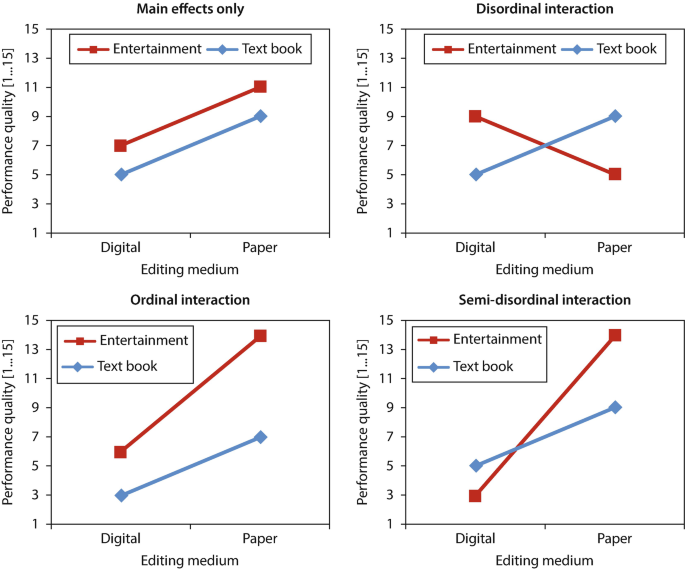
- null interaction: effects of factor A on the dependent variable are therefore the same at all stages of the factor B (parallel lines)
- ordinal interaction: effects of A are not the same at all factor levels of B (lines do not run parallel but do not cross)
- disordinal interaction: crossing lines (any main effects that may be present must not be interpreted)
- semi-disordinal: crossing lines or lines that do not cross (only one of the main effects that may be present may be interpreted)
9.2 Create score of political news attention

# recode into 'high', 'medium' and 'low'
sel$newsatt_r = NA
sel$newsatt_r <- ifelse((sel$newsatt>=1.5 &
sel$newsatt<=2.5), "2. medium",
as.character(sel$newsatt_r))
sel$newsatt_r <- ifelse((sel$newsatt<1.5 &
is.na(sel$newsatt_r)), "1. low",
as.character(sel$newsatt_r))
sel$newsatt_r <- ifelse((sel$newsatt>2.5 &
is.na(sel$newsatt_r)), "3. high",
as.character(sel$newsatt_r))
table(sel$newsatt_r)
1. low 2. medium 3. high
738 4791 1091 9.3 Example of ordinal interaction
The main effects and the interaction effect are significant:
Df Sum Sq Mean Sq F value Pr(>F)
newsatt_r 2 445 222.50 427.550 < 2e-16 ***
party 1 237 237.16 455.717 < 2e-16 ***
newsatt_r:party 2 8 4.01 7.698 0.000458 ***
Residuals 6614 3442 0.52
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
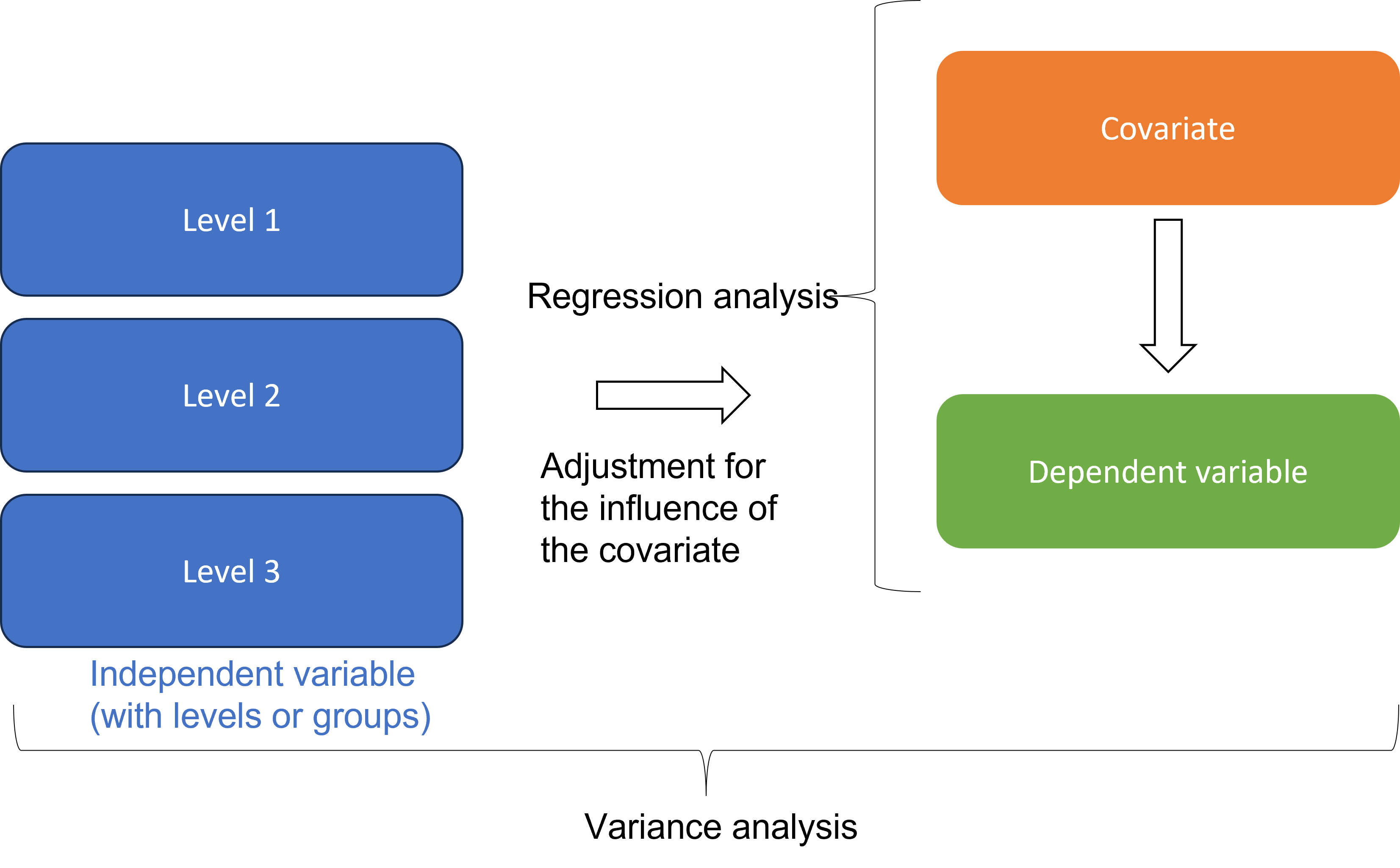
11.2 ANCOVA logic
15.6 Linearity
The pairwise relationship between the dependent variables should be linear for each group. This can be checked visually by creating a scatter plot matrix.
