library(foreign)
db <- read.spss(file=paste0(getwd(),
"/data/1184_Selects2019_Panel_Data_v4.0.sav"),
use.value.labels = T,
to.data.frame = T)
sel <- db |>
dplyr::select(W3_f11100,W3_f12800c,
W2_f13400a,W2_f13400b,W2_f13400c,W2_f13400d,
W2_f13400e,W2_f13400f) |>
stats::na.omit() |>
dplyr::rename("particip"="W3_f11100",
"party_trust"="W3_f12800c",
"tv"="W2_f13400a",
"newsp"="W2_f13400b",
"freen"="W2_f13400c",
"socmed"="W2_f13400d",
"online"="W2_f13400e",
"radio"="W2_f13400f") Moderation analysis presentation
Learn what moderation analysis is and how to run the analysis in R
1.1 Definition
Moderation analysis allows us to test for the influence of a third variable, Z, on the relationship between variables X and Y. Rather than testing a causal link between these other variables, moderation tests for when or under what conditions an effect occurs.
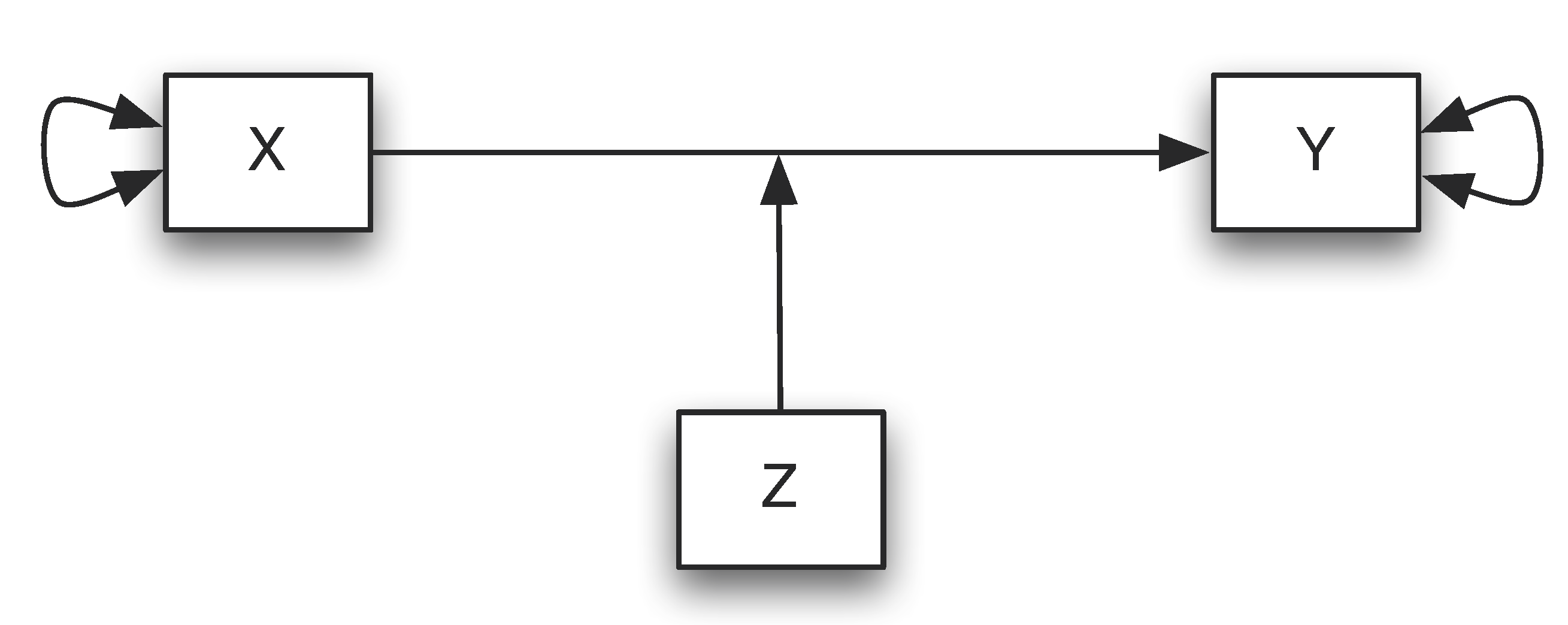
1.4 Illustration
See Igartua and Hayes (2021) for a complete discussion.

3.1 Simple slopes
When the moderation effect becomes significant, it needs to be “illustrated” in order to make it interpretable. To do so, we can rely on simple slope analysis: comparison of the regression lines for low, medium and high levels of the moderator.
Typically, we use the mean value of the moderator, as well as the values + and - 1 SD are used, but theoretically any values can be considered.

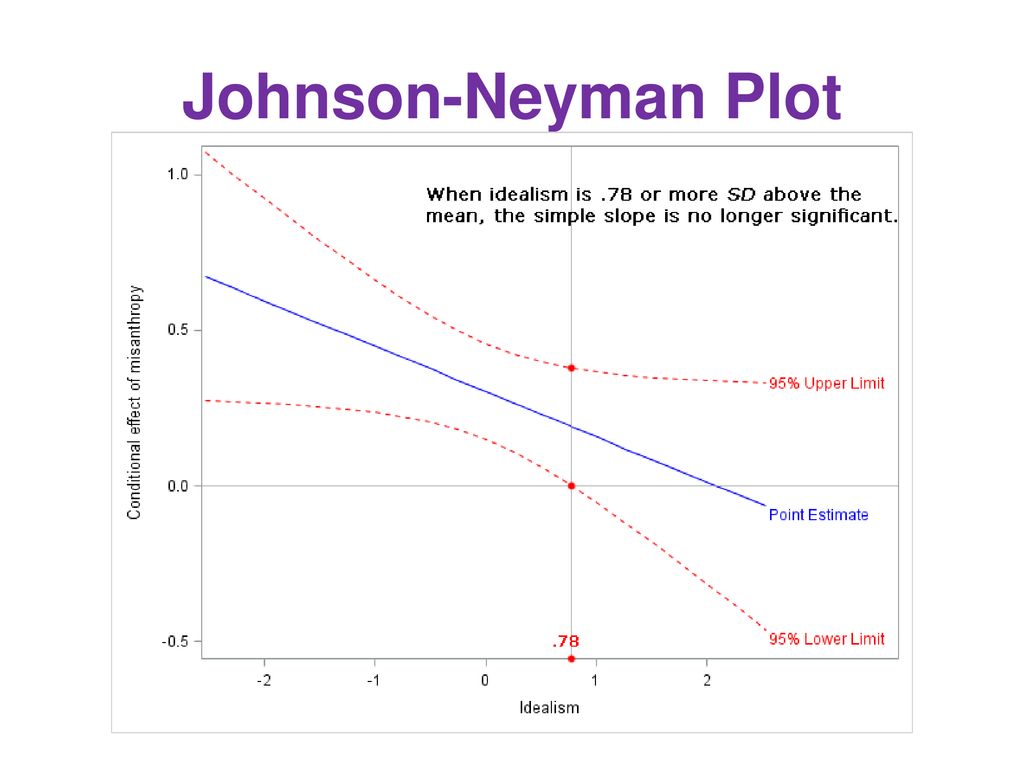
3.2 Significance range: Johnson & Neyman
This method suggests to conduct comparison of the regression equation for many characteristics of the moderator to identify areas of significance.
It is more useful than simple slopes for metric moderators, since illustrations result in less loss of information in the moderator’s levels. The effect (b) of the X on Y is now illustrated in the diagram as a function of the moderator (not to be confused with a regression line!), as well as the confidence interval for this effect:
5.7 Visualizations
The plot_model() function will automatically plot the simple slopes (1 SD above and 1 SD below the mean) of the moderating effect:


5.8 Moderator as categorical variable
We use a dichotomous moderator and check whether we obtain similar results:
===================================================
Dependent variable:
---------------------------
particip
---------------------------------------------------
party_trust_byes 0.364*** (0.084)
medatt 1.048*** (0.119)
party_trust_byes:medatt -0.287* (0.167)
Constant 1.247*** (0.061)
---------------------------------------------------
Observations 3,940
Log Likelihood -1,904.162
Akaike Inf. Crit. 3,816.324
===================================================
Note: *p<0.1; **p<0.05; ***p<0.01
![]()