1.1 Main differences between both approaches
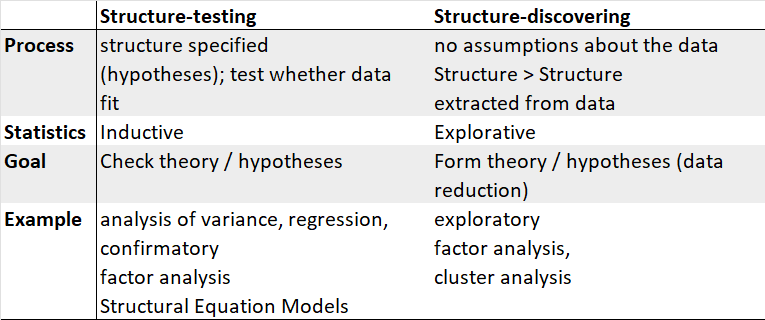
In EFA, all measured variables are related to every latent variable. It is used to reduce data to a smaller set of summary variables and to explore the underlying theoretical structure of the phenomena. Therefore, it requires interpretation.
In CFA, researchers can specify the number of factors required in the data and which measured variable is related to which latent variable. It asks how well a proposed model fits a given data. It does not give a definitive answer, but compares models (and data).