# load data
library(foreign)
db <- read.spss(file=paste0(getwd(),
"/data/1184_Selects2019_Panel_Data_v4.0.sav"),
use.value.labels = F,
to.data.frame = T)
sel <- db |>
dplyr::select(W3_Q04c,W4_Q04c,
W3_Q04b,W4_Q04b,
W3_Q04g,W4_Q04g) |>
stats::na.omit() |>
dplyr::rename("polit_trustworthy_1"="W3_Q04c",
"polit_trustworthy_2"="W4_Q04c",
"polit_carepeople_1"="W3_Q04b",
"polit_carepeople_2"="W4_Q04b",
"polit_rich_1"="W3_Q04g",
"polit_rich_2"="W4_Q04g")
for(i in 1:6){sel[,i] <- (as.numeric(sel[,i])-6)*(-1)}
for(i in 3:6){sel[,i] <- (sel[,i]-6)*(-1)}Structural equation modelling (SEM) presentation
Learn what SEM is and how to run the analysis in R
3.2 Graphical representation
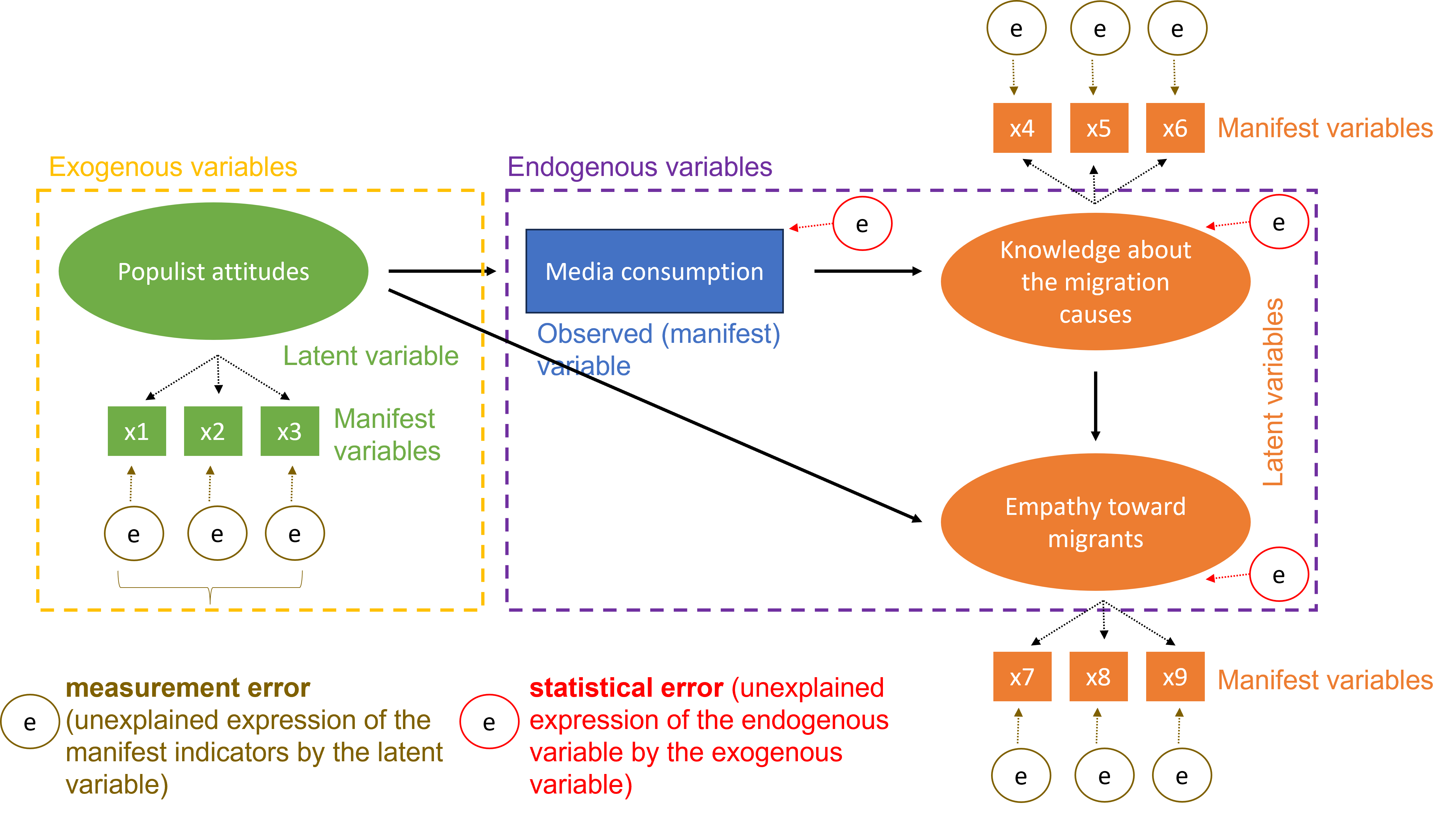
7.2 Problem statement
Assume we want to test whether trust in politicians before election can predict trust in politicians after election. Then the SEM model in the figure below can be used.
Note that we allow the factor in time 1 to predict the factor at time 2. In addition, we allow the uniqueness factors for each observed variable to be correlated.

7.5 Interpretation
print(paste0(
"Chi-squared ",
round(t[["test"]][["standard"]][["stat"]],3),
" with p-value ",
round(t[["test"]][["standard"]][["pvalue"]],3),
"; CFI: ", round(t[["fit"]][["cfi"]],3),
"; TFI: ", round(t[["fit"]][["tli"]],3),
"; RMSEA: ", round(t[["fit"]][["rmsea"]],3),
"; SRMR: ",round(t[["fit"]][["srmr"]],3)))[1] "Chi-squared 4.706 with p-value 0.453; CFI: 1; TFI: 1; RMSEA: 0; SRMR: 0.007"The chi-square value is 4.706 with 5 degrees of freedom. The p-value for chi-square test is almost 0.5. Thus, based on chi-square test, this is a good model (furthermore: CFI and TFI close to 1; RMSEA and SRMR about 0). Overall, this model is a fairly good model.
pe <- t[["pe"]]
pe <- as.data.frame(pe[!is.na(pe$pvalue),c(1,2,3,5,8)])
pe$est <- round(pe$est, 2); pe$pvalue <- round(pe$pvalue,2)
pe lhs op rhs est pvalue
2 polit_trust_1_latent =~ polit_carepeople_1 2.34 0.00
3 polit_trust_1_latent =~ polit_rich_1 2.20 0.00
5 polit_trust_2_latent =~ polit_carepeople_2 3.63 0.00
6 polit_trust_2_latent =~ polit_rich_2 3.39 0.00
7 polit_trust_1_latent ~ polit_trust_2_latent 1.22 0.00
8 polit_trustworthy_1 ~~ polit_trustworthy_2 0.24 0.00
9 polit_carepeople_1 ~~ polit_carepeople_2 0.09 0.01
10 polit_rich_1 ~~ polit_rich_2 0.30 0.00
11 polit_trustworthy_1 ~~ polit_trustworthy_1 0.73 0.00
12 polit_carepeople_1 ~~ polit_carepeople_1 0.56 0.00
13 polit_rich_1 ~~ polit_rich_1 0.74 0.00
14 polit_trustworthy_2 ~~ polit_trustworthy_2 0.81 0.00
15 polit_carepeople_2 ~~ polit_carepeople_2 0.54 0.00
16 polit_rich_2 ~~ polit_rich_2 0.71 0.00
17 polit_trust_1_latent ~~ polit_trust_1_latent 0.03 0.00
18 polit_trust_2_latent ~~ polit_trust_2_latent 0.04 0.00Trust before election seems to predict trust after election: those with higher trust in politicians before election tend to have higher trust level after election.
![]()