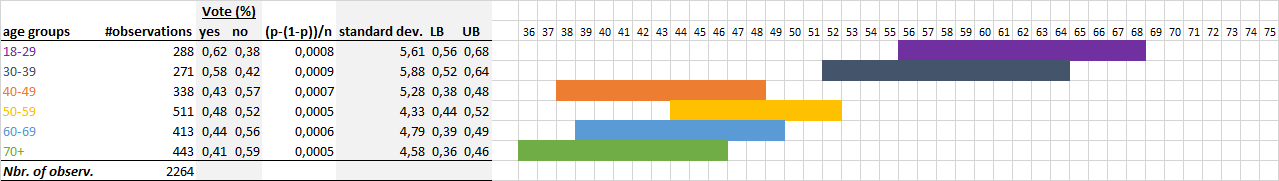[,1] [,2]
[1,] 7 12
[2,] 9 8
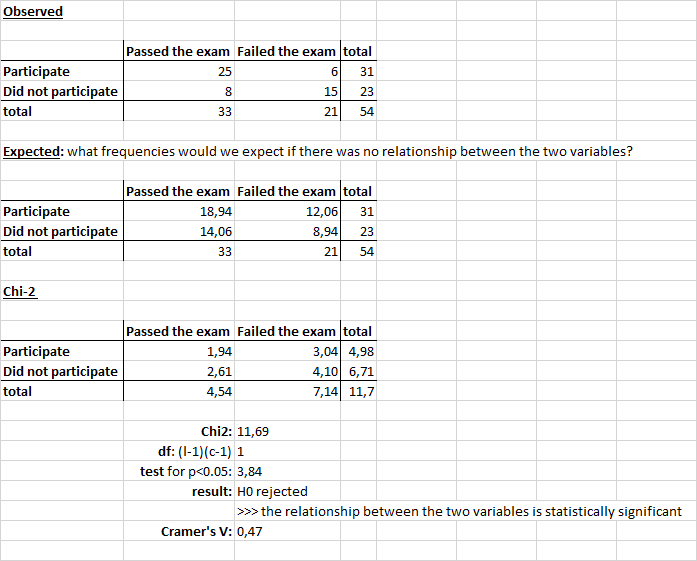
Pearson's Chi-squared test with Yates' continuity correction
data: data
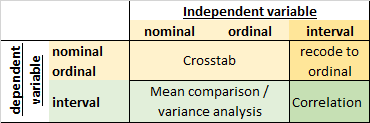
X-squared = 0.40263, df = 1, p-value = 0.5257[1] 0.1057554How to run bivariate analyses in R
The Total Survey Error (TSE) framework (Biemer, 2010) accounts for the different sources of errors that occur at each stage of an investigation (e.g. coverage errors, selection errors, and measurement errors). Two important concepts are: reliability and validity.
Reliability and validity
The margin of error is also called the confidence interval. It corresponds to the area where we know for a given probability that the average or the percentage of a value will be found.
For a mean: \(\overline{x}\pm1.96(\frac{\sigma(X)}{\sqrt{n}})\)
For a proportion: \(Z_\alpha\sqrt{\frac{p(1-p)}{n}}\)