Linear regression is a central method of analysis in the social sciences. In its simplest form, it resembles bivariate analysis of two metric variables. It is also an important method as it allows an easy transition to multivariate data analysis (multivariate regression) and as it allows an extension to categorical data analysis (logistic, ordinal logit, and multinomial logit models), as well as hierarchical models.
Linear regression helps us in answering typical questions, such as the existence of a relationship (dependence) between an independent variable (e.g., education) and a dependent variable (e.g., income). It also provides us with information about the strength and the robustness of this relationship (e.g., by controlling for other variables in the model).
3.2 Excurse: correlation is no proof of causality
Social sciences often rely on (survey) data that were collected for a population of interest. When data are collected at a single point in time (rather than repetitively for the same individuals), the main focus of the research is about whether two phenomena are correlated. Correlation examines association of two metric variables (interval/ratio level) and measures the direction and strength to which two variables are related (between -1 and +1), most often using Pearson’s correlation coefficient.
Assessing causality between two phenomena requires additional features beyond correlation. It also requires that a phenomenon X comes before a phenomenon Y, thus relying on longitudinal data or, with more theoretical argumentation, cross-sectional data. It also requires that the correlation between X and Y remains if we control for further relevant variables.
3.3 Simple linear regression
Tip from the tutors
When you are learning a new method (model) think about it in the following way: Application (Purpose, Key Concepts, Extensions/Variations) > Preliminary Tests and Assumptions > Significance Testing and Interpretation > Strength of Relationship / Model Quality.
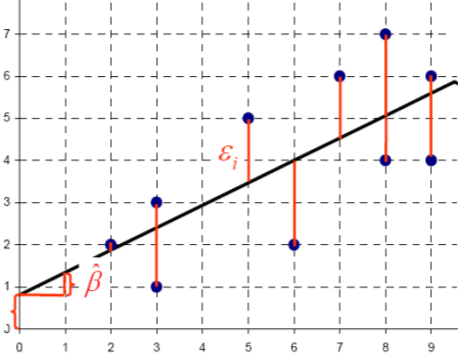
In its simplest form, linear regression is a way of predicting value of one variable Y through another known variable X. It is a hypothetical model which uses the the equation of a straight line (linear model) based on the method of least squares which minimize the sum of squared errors (SSE). What does this mean?
Let’s take a basic example covering the relationship between years of education (X) and income (Y). Here, a research question could be: Which income can be attained with ten years of education? Answering this question requires finding the best fitting line between the two variables and provides us with the formula:
where \(\mathbf{\hat{y_i}}\) is the estimated income for an individual, \(\mathbf{a}\) is the constant (or intercept: value where education equals 0), \(\mathbf{x_i}\) is the value of education for an individual, and \(\mathbf{b}\) is the effect size of education on income (or slope: change in income by a change in education). The equation for the slope is represented by dividing the covariance over the variance:
In principle, there are plenty of lines through the data and the line with the lowest SSE represents the line which best fit the data. In our example, the predicted income deviates from the observed income, because all values are not lying precisely on a line. Therefore, we need to estimate a regression line where distances (errors) between the predicted and observed values are minimized. The residuals read as follows:
Up to here, we are able to interpret the slope coefficient, which gives us the direction of the effect (+ of -) and the extent to which Y changes if X increases by 1. However, we also need to assess the statistical significance of the effect. Indeed, the slope coefficient represents the point estimator (sample) for the “true” population value (\(\beta\)). Here, the standard error provides us with a measure for the variability (dispersion) of \(\mathbf{b}\) and, thereby, the confidence intervals to test significance of the effect. In this case, the null hypothesis states that there is no relation between X and Y (using the t-statistic).
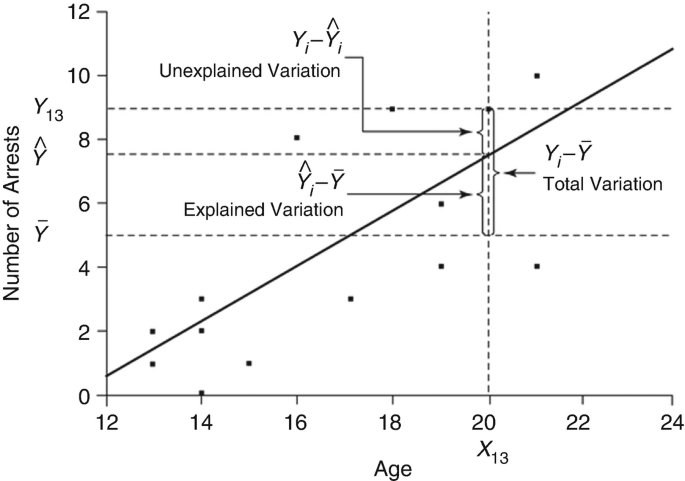
3.4 Total variation
How much variance is there on the Y? We are interested in the overall variation. Therefore, without knowing X, the mean of Y is the best estimate for all Y values. This is also called the “baseline model” and the resulting error is called total variation: \(TSS = \sum{(Y_i - \overline{Y})^2}\).
However, knowing X, the regression line is a better estimate for Y. The resulting error is the residual variation (“residuals”): \(SSE = \sum{(Y_i - \hat{Y}_i)^2}\).
Therefore, the explained variation in the regression model is: \(MSS = \sum{(\hat{Y}_i - \overline{Y})^2}\).
In real world, the relations between two variables are often influenced by “third variables”. In this case, the bivariate association is not informative if not controlling for the disturbing influence of a third, fourth, fifth, etc. variable (with different measurement levels). Multivariate regression takes the influence of other variables on the relation between two variables into account. Therefore, it is powerful to detect spurious- and suppressor effects, indirect effects, and interaction effects. This goal is to estimate the “net” influence of several independent variables:
In multivariate models, the \(b\) coefficient represents the “raw” regression coefficient. It is important to note that the comparison of \(b\) coefficients is not meaningful if the variables are measured in different units (e.g. working time in hours & family size in number of individuals). A possible solution is the standardization of the variables (mean=0 & standard deviation=1) in view of assessing which independent variable has greater effect on Y (relative contribution). The standardized \(b\) (written by convention \(\beta\)) are often referred as the beta coefficients. In a simple linear model, \(\beta\) corresponds to Pearson \(r\). The interpretation of the \(\beta\) coefficient indicates by how many standard deviations Y varies when X varies by one standard deviation.
3.6 Explained proportion of the variance
\(R^2\) provides us with a measure of accuracy of the regression model, that is how well does the regression line approximate the real data points. It represents the share of explained variance (how much variation in Y is explained through X) and varies between 0 and +1. \(R^2\) tends to increase as we increase the number of variables in the model.
\(R^2\) does not tell us whether the independent variables are true cause of changes in Y (no causality), whether omitted-variable bias exists (third variable problem), whether the correct regression was used, and whether appropriate independent variables have been chosen. In research, our focus is often only one part of a complex story.
\(R^2\) explained
In addition to the direction, strength and significance of the effect of the \(\mathbf{b}\) coefficient, multivariate model also provide a coefficient of determination \(R^2\), which can be expressed as follows:
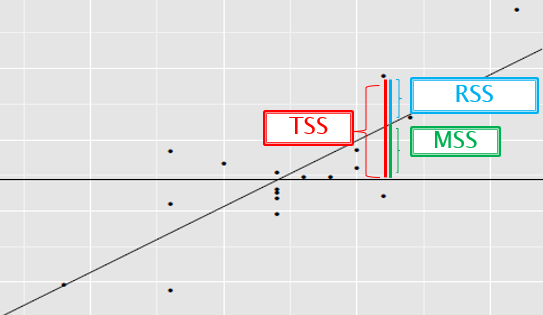
MSS is the model sum of squares (also known as ESS, or explained sum of squares). It is the sum of the squares of the prediction from the linear regression minus the mean for that variable.
TSS is the total sum of squares associated with the outcome variable, which is the sum of the squares of the measurements minus their mean.
RSS is the residual sum of squares, which is the sum of the squares of the measurements minus the prediction from the linear regression.
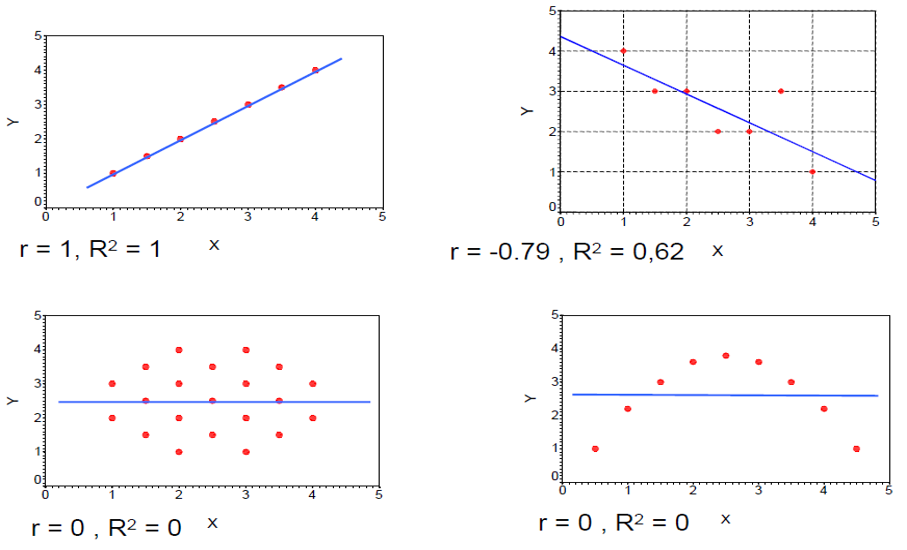
3.7 Relationship between \(r\) and \(R^2\)
If X and Y are two metric variables, \(R^2\) is a measure of a linear relation between X and Y, while \(r\) (Pearson correlation) is the empirical correlation between X and Y. Importantly, in bivariate regression, \(R^2 = r_{xy}^2\) (where \(r\) is a standardized regression coefficient). In multiple regression, \(r\) represents the correlation between the observed \(y\) values and the predicted \(\hat{y}\) values.
3.8 F-test for the regression model
F-test is a global check of the regression model. It tests the hypothesis whether in the population there is a connection between the Y and the X:
H0: no connection (or \(R^2\) = 0)
H1: there is a connection (or \(R^2\) not equal 0)
F-test explained
\[ MS_M = \frac{MSS}{k} \]\[ MS_R = \frac{SSE}{N-k-1} \] , where k is the number of independent variables and N is the number of individuals. \[ F = \frac{MS_M}{MS_R} \]
3.9 Standard estimation error
The standard estimation error characterizes the spread of the y-values around the regression line and is therefore a quality measure for the accuracy of the regression prediction:
The standard error of estimation comes from the fact that:
Part of the estimation error can be attributed to chance (e.g. “human randomness”)
Part is determined by predictors that are not included in the model
Part of the estimation error arises from measurement errors
FAQ on the standard error of estimation
What contributes to the standard error of estimation? The standard error of estimation increases with:
large k, since k is subtracted in the denominator
if the residuals are large.
Nota bene: if n is large, the estimation error does not automatically decrease! This is because for every observation there is also a deviation that is included in the calculation of the total.
How do standard estimation errors, intercept and slope behave to each other? The intercept and slope have nothing to do with explained or unexplained variance, so nothing to do with the standard error of estimation either.
3.10 Overfitting
The regression equation is always exactly identified if the number of observations is only one higher than the number of independent variables (if: n-1 = k). There are only sufficient “degrees of freedom” if there are more measuring points (observations) than variables. Only if the deviations are small, then we are talking about a high quality of fit of the regression calculation.
However, specific sample features only apply to one sample, not to the total population and not to other samples either. They should not be allowed to contribute to model quality. As a consequence, the estimate always tends to be too high. That means:
The estimated Y values and the empirical Y values correlate (probably) stronger than in reality
The residuals are smaller than they should actually be (according to the conditions in the population)
The explained variance is consequently greater than it should be
3.11 Shrinkage
The determination coefficient often turns out to be smaller with a new sample. This phenomenon/principle is called shrinkage. Therefore, a corrected \(R^2\) (adjusted \(R^2\)) takes this into account by reducing the simple \(R^2\) by a correction value that is larger: the larger the number of predictors and the smaller the number of cases (whereas the simple \(R^2\) increases with each added predictor, the corrected \(R^2\) can increase or decrease as more predictors are added).
Adjusted \(R^2\) explained
Adjusted \(R^2\) is a corrected goodness-of-fit (model accuracy) measure for linear models. Because \(R^2\) tends to optimistically estimate the fit of the linear regression (as it typically increases as the number of effects are included in the model), adjusted \(R^2\) attempts to correct for this overestimation. Adjusted \(R^2\) might even decrease if a specific effect does not improve the model.
Adjusted \(R^2\) is calculated as follows:
\[ R^2_{adj} = 1 - [\frac{(1-R^2)(n-1)}{(n-k-1)}] \] where \(n\) represents the number of data points and \(k\) the number of independent variables.
So, if \(R^2\) does not increase significantly on the addition of a new independent variable, then the value of adjusted \(R^2\) will actually decrease. But, if adding the new independent variable leads to a significant increase in \(R^2\) value, then the adjusted \(R^2\) value will also increase.
3.12 Statistical significance
A t-test is used to determine whether the regression coefficients deviate significantly from zero (H0). To calculate the t-value per coefficient, the standard error (\(S_b\)) of each coefficient is also necessary. The \(S_b\) characterizes the spread of the regression coefficients around the population parameter and is therefore a quality measure for the accuracy of the parameter estimation. The larger the SE, the smaller the empirical t-value and the less likely it is that the H0 will be rejected.
The significance of the effect is based on the ratio between a coefficient and its standard error. This is the empirical value of the t-test (\(t=b/S_b\)), which is compared with a critical value (c.v.=1.96). The null hypothesis (H0) is accepted if the critical value is < 1.96. The confidence interval should not contain 0.
Confidence interval for the regression slope
3.13 Dummy variables
Categorical independent variables are problematic because the numeric codes assigned to their categories are arbitrary (when the code changes, the estimate changes). A solution suggests associating a binary dummy variable with each modality (coded 0 and 1). A categorical variable with c modalities is replaced by c-1 dummies.
The omitted modality serves as a reference category. The choice of the reference category is made on the basis of empirical considerations (e.g., modality with the largest number of cases or modality that makes sense from a theoretical point of view). The coefficients b are interpreted with respect to the reference category.
3.14 Postulates and assumptions
Linear regression requires using numerical variables (or dichotomous for the independent variables). A dichotomous variable is always coded 1 and 0. Linear regression entails several premises:
A regression model should contain exactly those independent variables that are relevant for the dependent variable, no more and no less. Bivariate regression models, for example, are always misspecified. The risk with having too few variables is underfitting, thus leading to too high regression coefficients insufficient explanations. The risk with too many/irrelevant variables is overfitting, thus leading relevant significances to disappear and/or random significance to arise. To conduct linear regression, we must have sufficient degrees of freedom. In general, this corresponds to at least 10 (or 20) times more cases than variables.
Linear regression only works well for (almost) normally distributed variables. When normality does not apply, we might think about transforming the variables (e.g., log, powers, etc.).
There must be an independence of the independent variables, that is an absence of multicollinearity between the independent variables. Regression coefficients can be biased if there is a strong correlation between two independent variables.
Furthermore, the error terms must be distributed according to a normal law and should be zero on average.
There must also be an independence of error terms (to be checked when we have time series).
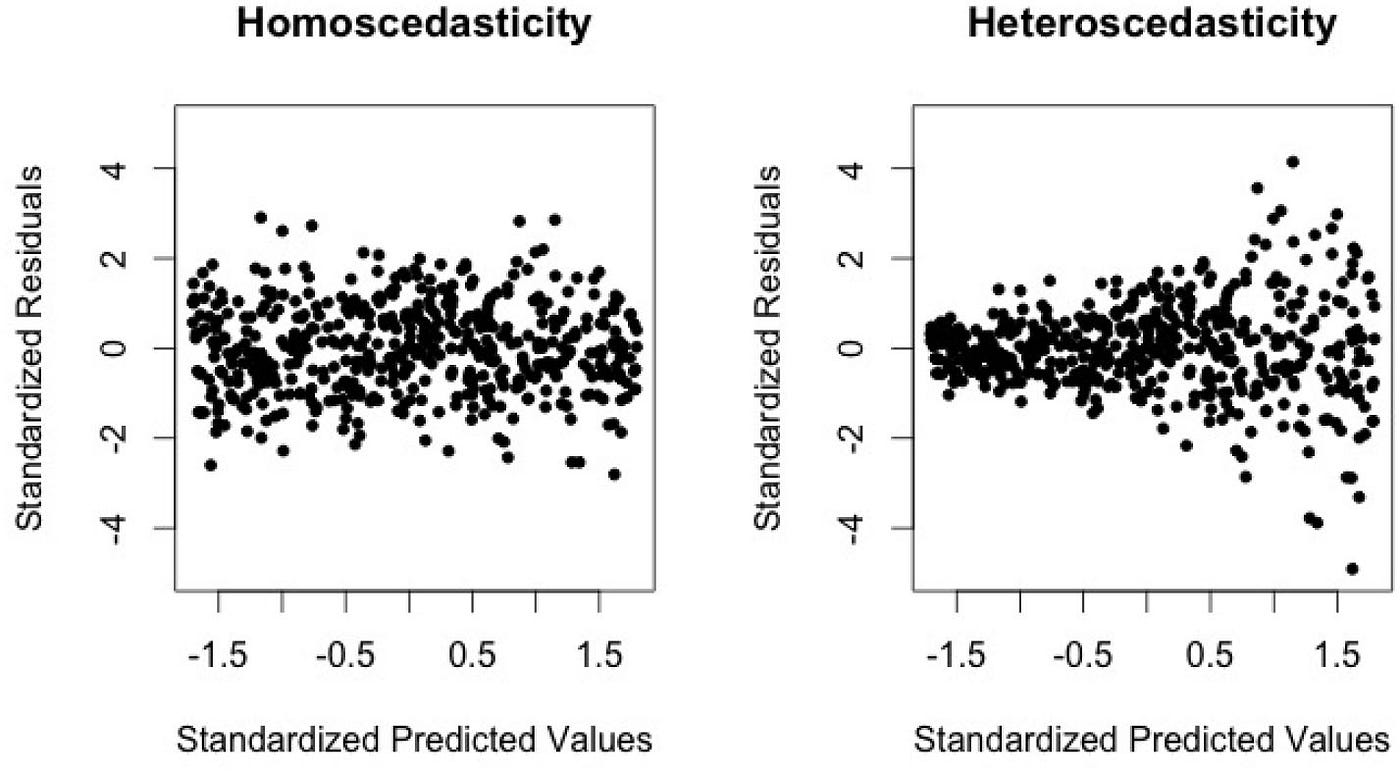
Linear regression also requires homoscedasticity, that is the fact that the variance of the error terms is constant for all values of the independent variables.
The premises can be tested as follows:
Linear regression diagnostics
3.14.1 Multicollinearity
Multicollinearity is not a severe violation of linear regression (only in extreme cases). In the presence of multicollinearity, the estimates are still consistent, but there is an increase in standard errors (estimates are less precise). The problem occurs when researchers include many highly correlated variables (e.g., age and birth year). Therefore, there should be a theory-driven, careful, and intelligent variable selection.
Collinearity statistics include the Tolerance which varies from 0 to 1 and must be >0.4. The VIF (variance inflation factor) measure can also be used which varies from 1 to \(\infty\) and must be <2.5 (which corresponds to a Tolerance of 0.4). Note that there is an inverse relationship between Tolerance and VIF values. As such, Tolerance values >0.4 and VIF values <2.5 are signs of no serious multicollinearity among the variables.
If there is multicollinearity, there are basically two solutions: either eliminating one (or more) problematic variables, or merging the problematic variables (e.g., in a scale).
Tolerance = \(1-R^2\)
VIF = \(1/(1-R^2)\)
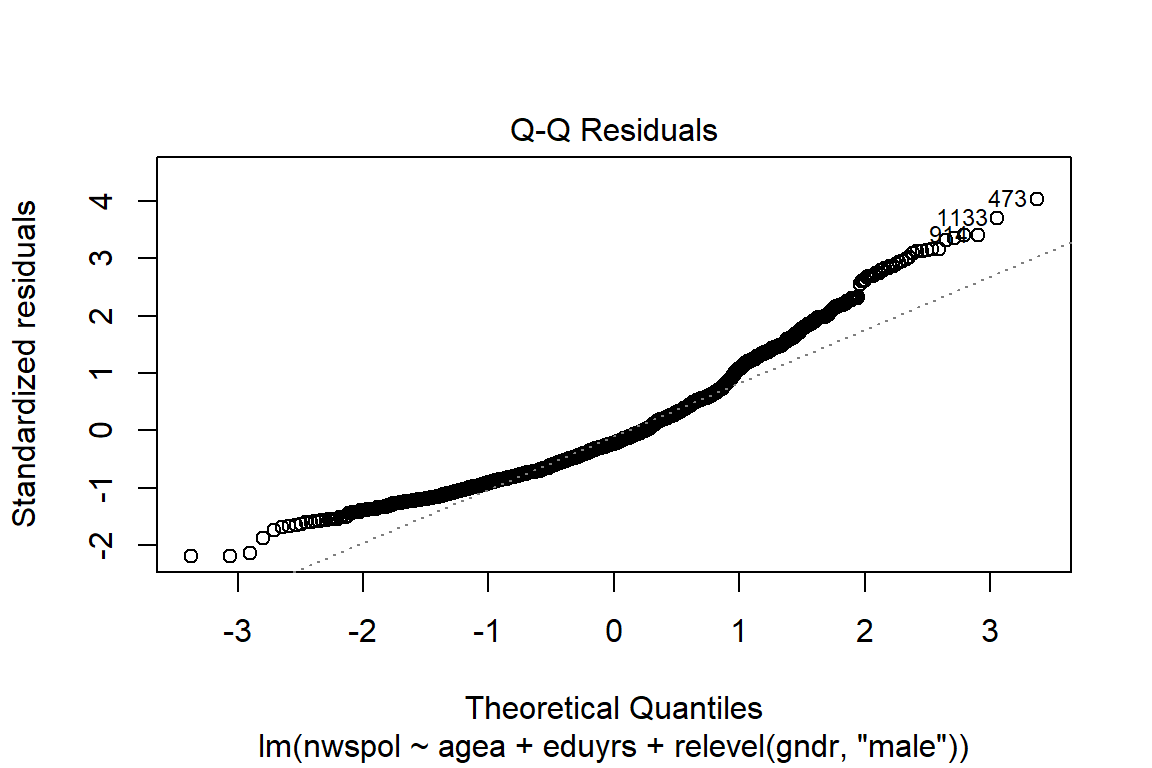
3.14.2 Normal distribution of the residuals
The residuals must be normally distributed. For instance, the deviations between estimated and observed values should be zero or close to zero in most cases. Risks of non-normal residuals result in biased results, thus the significance tests are biased. As a reminder:
for every empirical value Y there is an estimated value Y and a residual
the larger the residual for an estimate, the worse the regression estimate for this estimate
the larger the residuals are overall, the larger the standard estimation error (“mean” of the squared residuals), and the poorer the overall goodness of fit of the regression estimate
3.14.3 Autocorrelation of the residuals (independent errors)
The non-independence of the residuals occurs when sampling is not independent of one another, i.e. systematically related (time series data, periodic surveys). In these cases, the risks are:
Bias in the standard error of the regression coefficients
Bias in the confidence interval for the regression coefficients
We can verify this using the Durbin-Watson statistics.
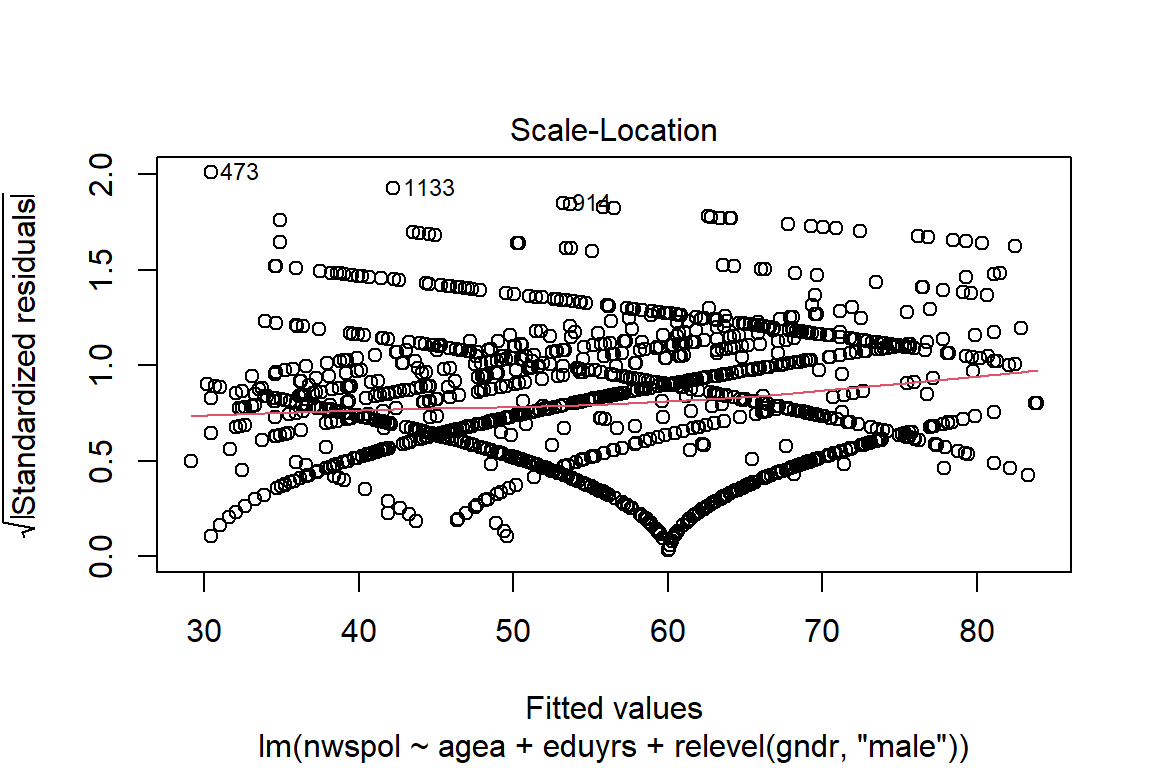
3.14.4 Homoscedasticity
Heteroscedasticity is present when there is a relationship between the estimated y-values and the residuals of the observation values. This can be verified by a visual inspection - no pattern should be discernible.
3.15 Outliers
The impact of an observation is depending on two factors. First, the discrepancy (or outlierness) which assesses observations with large residual (observations whose Y value is unusual given its values on X). Second, the leverage which assesses observations with extreme value on X with the general rule:
\[lev>(2k+2)/n)\]
A “high leverage” outlier impacts the model fit, may not have big residuals, and can increase \(R^2\).
A “low leverage” outlier has a lower impact on the model fit, has usually a big residual, inflates standard errors, and decreases \(R^2\).
There are several strategies to identify outliers, such as conducting frequency analysis one variable, using the scatterplots for two variables, looking at the n highest and lowest values, and investigating the residuals (through partial residual plots or added value plots), as well as relying on influential measures. For instance:
Cook’s Distance with the general rule: \(d>4/(n-k-1)\)
dfbeta with the general rule: \(2/\sqrt{n}\))
Note that there might be cases where we want to keep outliers. This may include cases where we have meaningful cluster (e.g., important subgroup in the data) or cases where outliers might reflect a “real” pattern in the data. In these cases, it is important to present the results both with and without outliers.
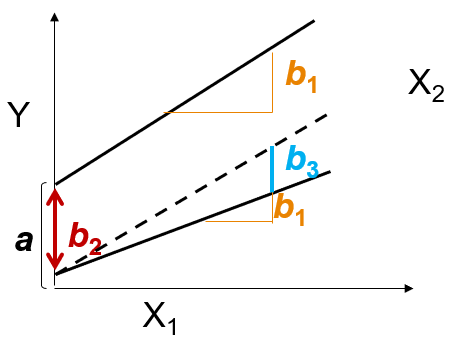
3.16 Interaction effects
Interaction effects enable us to model non-additive effects. In additive models, the effects of independent variables are the same for the complete sample (e.g., effect of education on income is the same for women and men). But, theoretically, effect should differ for different groups (e.g., women and men).
Interaction effects suggest that the strength of the association between \(x_1\) and\(y\) is dependent on the level of a third variable \(x_2\):
Categorical variables (qualitative variables) refer to a characteristic that can’t be quantifiable. They can be either nominal or ordinal. Nominal variables describe a name, label or category without natural order (e.g., sex, marital status, race, etc.). Ordinal variables are defined by an order relation between the different categories (e.g., ranking of students, sport clubs, social class, etc.).
Numeric variables (quantitative variables) is a quantifiable characteristic whose values are numbers. Numeric variables may be either continuous or discrete. Discrete (or interval) variables assume only a finite number of real values within a given interval (e.g., people in a household, temperature, etc.). Continuous (or ratio) variables can assume an infinite number of real values within a given interval (e.g., height/weight of a person).
3.16.2 Interaction between interval variables
For instance, we might be interested in the effect of age (\(x_1\)) on income (\(y\)) depending on years of schooling (\(x_2\)). In this case, the interpretation of the main effect of \(x_1\) is the effect of \(x_1\) if \(x_2\) equals 0 (and conversely for \(x_2\)). The interpretation of the interaction effect is done by calculating the effect of \(x_1\) on \(y\) for different levels of \(x_2\) (and conversely for \(x_2\)).
Note that the interpretation of interval variables might be problematic if the zero value is not meaningful (e.g., age=0). A better interpretation of the main effects can be obtained by centering the variables (through subtracting the mean score from each data-point). In this case, the interpretation of the intercept (\(a\)) also changes and represents the predicted value of \(y\) if \(x\) is the average.
3.16.3 Interaction between dummy and interval variables
For instance, we might be interested in how the association between years of education (\(x_1\)) and income (\(y\)) varies by gender (\(x_2\), where 1=women and 0=men). In this case, the slope (\(b\)) and intercept (\(a\)) of the regression of \(x_1\) on \(y\) are dependent on specific values of \(x_2\). Therefore, for each individual value of \(x_2\) (e.g., 0/1) there is a regression line. The general interpretation rules suggest that the main effect of \(x_1\) represents the effect of \(x_1\) if \(x_2\) equals 0 (and conversely for \(x_2\)). Thus, the interaction effect indicates how much the effect of \(x_1\) changes with an unit change in \(x_2\) (and conversely for \(x_2\)).
3.16.4 Interaction between ordinal and nominal variables
For instance, we might be interested in how the association between the fact of having a child (\(x_1\), where 1=having (at least) a child and 0=no child) and income (\(y\)) varies by gender (\(x_2\), where 1=women and 0=men).
3.16.5 In a nutshell
Linear regression is a statistical method used to examine and predict the relationship between a dependent variable (Y) and one or more independent variables (X). The aim is to find the best-fitting line through the data using the least squares method, minimizing the distance between observed and predicted values.
Logic: In simple regression, the slope shows how much Y changes when X increases by 1, while the intercept is Y when X = 0. In multivariate regression, additional variables are included to estimate the net effects, control for confounders, and detect interaction effects (when the effect of one variable depends on another).
Assumptions: Models require relevant predictors, linear relationships, normally distributed and independent residuals, absence of multicollinearity, and homoscedasticity (constant error variance).
Model quality: The \(R^2\) statistic shows the proportion of variance in Y explained by the model (adjusted \(R^2\) corrects for overfitting). The F-test checks whether the model overall improves prediction compared to no predictors. Individual coefficients are tested with t-tests for statistical significance.
Definition: In short, linear regression is a tool for quantifying, testing, and interpreting linear relationships between variables, balancing explanatory power with adherence to statistical assumptions.
3.17 How it works in R?
See the lecture slides on linear regression:
You can also download the PDF of the slides here:
3.18 Quiz
True
False
Statement
The coefficients of the least squares regression line are determined by minimizing the sum of the squares of the residuals.
A residual is computed as an x‐coordinate from the data minus an x‐coordinate predicted by the line.
Interaction effects enable us to model non-additive effects.
The variance inflation factor (VIF) can be used to identify this issue of multicollinearity.
My results will appear here
3.19 Example from the literature
The following article relies on linear regression as a method of analysis:
Rauchfleisch, A., & Metag, J. (2016). The special case of Switzerland: Swiss politicians on Twitter. New Media & Society, 18(10), 2413-2431. Available here.
Please reflect on the following questions:
What is the research question of the study?
What are the research hypotheses?
Is linear regression an appropriate method of analysis to answer the research question?
Solution
OLS linear regression is reasonable for RQ1 (predicting a continuous rate like messages/day, with caveats about skew/outliers which they address via bootstrapping). It is less appropriate for RQ3, where the outcome is a count (number of journalist followers), for which a Poisson/negative binomial (or logged OLS) would typically be better; and not suited to RQ2, which is a network/association question.
What are the main findings of the linear regression analysis?
And some more questions from the tutors:
How should we interpret the coefficient for Age as birth year (0.021, p < .01) in terms of the expected change in messages per day?
Solution
For each one-year increase in birth year (i.e., younger politicians), the number of messages per day increases by 0.021, holding all else constant. This effect is statistically significant (p < .01).
Given that the R² is 0.1681 and only urbanization and age show significant effects, what does this suggest about the explanatory power of the model and the relative importance of the predictors included?
Solution
The R² of 0.1681 means the model explains about 17% of the variance in messages per day. Among the predictors, Age (birth year) has the strongest and most robust effect, both statistically (p < .01) and in magnitude. Urbanization also has a significant but weaker effect: for each 1% increase in canton urbanization, messages per day increase by 0.008 (p < .05). Other predictors (gender, newcomer status, party size) are not significant and do not meaningfully contribute to explaining variation.
Holding all other variables at 0, what is the number of messages per day? Can we meaningfully interpret it and why?
Solution
-42 messages per day, so no meaningful interpretation not only because it is negative, but also because the age as birth year would not be meaningful.
In your own words, explain the difference between R² and adjusted R² and interpret the adjusted R² of 0.1127.
Solution
The adjusted R² corrects R² by penalizing for adding predictors, decreasing as more predictors are added (especially if the sample size is small). The adjusted R² value of 0.1127 means that when accounting for the number of predictors added, the model explains about 11% of the variance in messages per year.
Explain what the F-statistic of 3.302** means.
Solution
The F-statistic measures the spread of Y-values around the regression line, indicating the accuracy of predictions (goodness of fit). In this model the F of 3.302 means that the model explains about 3.3 times more variance per predictor than the residual variance.
3.20 Time to practice on your own
You can download the PDF of the exercises here:
The exercises 1 and 2 will use the data from the round 10 of the European Social Survey (ESS). You can download the data directly on the ESS website.
The objective is to conduct linear regression to explain the consumption of news about politics and current affairs (‘nwspol’: watching, reading or listening in minutes). Explanatory variables include a set of political and sociodemographic variables. Political variables can include: political interest (‘polintr’), confidence in ability to participate in politics (‘cptppola’), and self-placement on the left-right political scale (‘lrscale’). Sociodemographic variables can include: gender (‘gndr’), age (‘agea’), and years of education (‘eduyrs’). You can also decide to rely on additional or alternative variables.
Let’s start by loading the dataset, selecting the relevant variables, and filtering the data for Switzerland only:
Show the code
library(foreign)db <-read.spss(file=paste0(getwd(),"/data/ESS10.sav"), use.value.labels = F, to.data.frame = T)sel <- db |> dplyr::select(cntry, nwspol, polintr, cptppola, lrscale, gndr, agea, eduyrs) |> stats::na.omit() |> dplyr::filter(cntry=="CH") # select respondents from Switzerland# verify the class and range of the variablessel$nwspol=as.numeric(sel$nwspol)sel = sel[sel$nwspol<=180,] # maximally 3hours of news consumptionsel$gndr =as.factor(sel$gndr)sel$gndr =ifelse(sel$gndr=="2", "female", "male")sel$gndr =as.factor(as.character(sel$gndr))
3.20.1 Example 1: stepwise regression
Conduct your own linear regression analysis by following a stepwise logic:
The variable that shows the highest correlation with the dependent variable is selected (in absolute terms)
The variable measuring political interest displays the highest correlation (in absolute term) with the news consumption. Note that the correlation is negative because political interest in measured with the item “How interested would you say you are in politics - are you…” where the response scale is as follows: 1 for “Very interested” and 4 for “Not at all interested”. Ideally, we would reverse the scale before running the analyses and interpreting the results.
Concerning the regression model, the coefficient for political interest is -14.301 (so, +14.301 with a reversed scale) and its effect is significantly impacting news consumption (p < 0.001). The proportion of explained variance is given by an \(R^2\) of 0.10 (or 10%).
The variable that has the highest semi-partial correlation with the dependent variable from the remaining variables is then selected (in absolute terms). The semi-partial correlation coefficient is the correlation between all of Y and that part of X which is independent of Z.
The variable with the highest semi-partial correlation is age. Therefore, we include it in the regression model. We see that the effect of political interest remains significant. Furthermore, the effect of age is positively impacting news consumption (coef = 0.54) and that it is also significant (p < 0.001). Note that we cannot compare the effect of political interest and age as the variables have not been standardized. The proportion of explained variance is given by \(R^2\) and is now 0.16 (or 16%). Each time check whether adding more variables significantly improves the model.
3.20.2 Example 2: deductive approach
Conduct your own linear regression analysis by following a deductive logic:
Include the independent variables simultaneously in the regression equation
Adding all the variables together in the model shows that only political interest and age are significantly impacting on news consumption. The proportion of explained variance is given by \(R^2\) and remains at 0.16 (or 16%). Adding more variables did not significantly improve the model.
Include hierarchically (blockwise) the independent variables into groups and include them in the regression equation group by group (e.g. sociodemographic variables first and political variables then).
Including only sociodemographic variables (age, gender and years of education) shows that age and gender (with “male” as the reference category) are statistically significant (p < 0.001 and p = 0.04 respectively). The proportion of explained variance is 0.10 (or 10%).
Each time check whether the (groups of) variables significantly improve the model.
Show the code
cat(paste0("R2 from the model with sociodemo variables is: ", round(summary(regbs)$adj.r.squared,3), "\n","R2 from the model including all the variables is: ",round(summary(regbt)$adj.r.squared,3)))## R2 from the model with sociodemo variables is: 0.098## R2 from the model including all the variables is: 0.165
Interpretation
The proportion of explained variance is 0.10 (or 10%) for the model with only sociodemographic variables, while it is 0.16 (16%) for the model containing all the variables. However, we have seen that only age and political interest are significantly related to news consumption (gender looses its significance in the model containing all the variables).
3.20.3 Example 3: postulates and assumptions
Based on the previous regression model, evaluate the assumptions of linear regression: no multicolinearity, normality of the residuals, no auto-correlation of the residuals (especially for time series and panel data), homoscedasticity. It is also important to check for outliers.
First, we want to check for multicollinearity. In case of multicollinearity issue, regression model is not able to accurately associate variance in the outcome variable with the correct predictor variable, leading to incorrect inferences. Beyond theoretical reflections, there are several steps to test for multicollinearity issues, such as correlation, VIF (and tolerance):
The correlation matrix does not point to very high correlations (e.g., > 0.7). Furthermore, the VIF (<2.5) and Tolerance (>0.4) show no sign of multicollinearity.
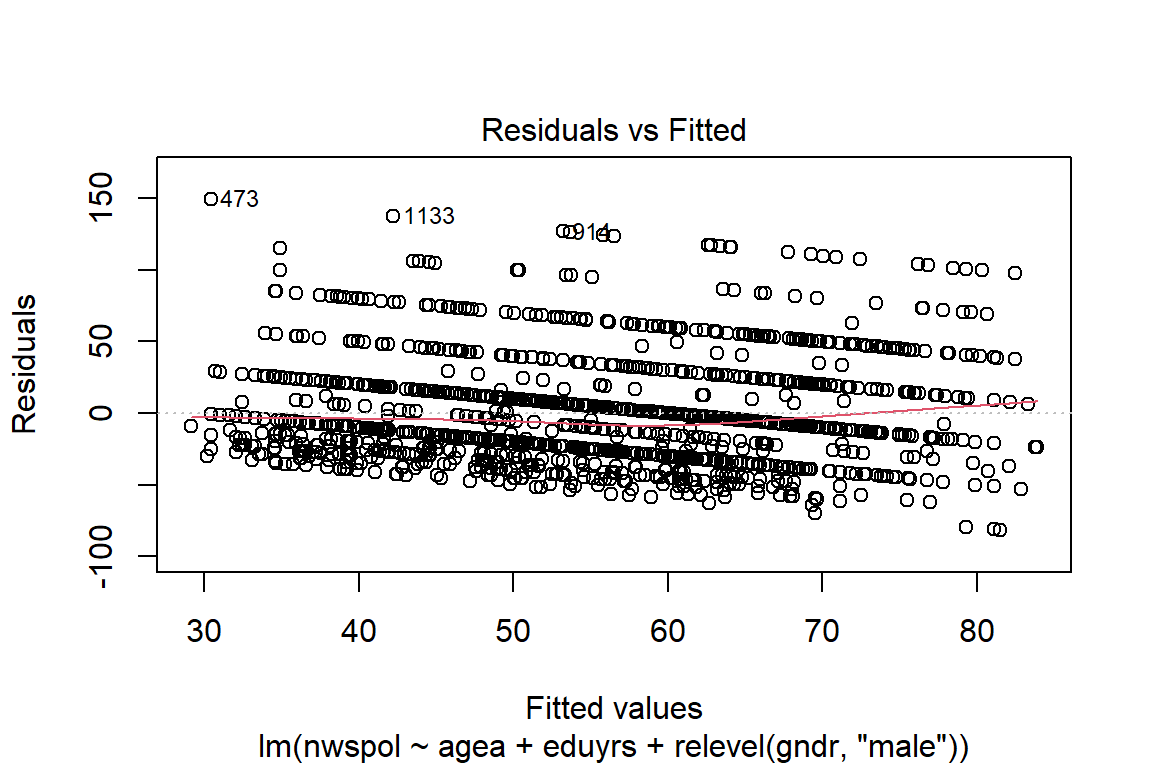
Second, we can test for the normality of the residuals. We can examine the normal Predicted Probability (P-P) plot to determine if the residuals are normally distributed (ideally, they they will conform to the diagonal normality line):
Show the code
plot(regbs, 2)
Interpretation
In order to make valid inferences, the residuals of the regression (differences between the observed value of the dependent variable and the predicted value) should follow a normal distribution. This is approximately the case here.
Third, we can check for homoscedasticity (variance of the error terms should be constant for all values of the independent variables). In the context of t-tests and ANOVAs, the same concept is referred to as equality (or homogeneity) of variances. We can check this by plotting the predicted values and residuals on a scatterplot:
Show the code
plot(regbs, 3)
Interpretation
The residuals need to be spread equally along the ranges of predictors (ideally, there should be a horizontal line with equally spread points). This is the case here.
We can also check for linearity of the residuals:
Show the code
plot(regbs, 1)
Interpretation
The predictor variables in the regression should have a straight-line relationship with the outcome variable (ideally, the plot would not have a pattern where the red line is approximately horizontal at zero). This is the case here.
Nota bene: Using the Durbin-Watson test, we can test the null hypothesis stating that the errors are not auto-correlated with themselves (if p-value > 0.05, we would fail to reject the null hypothesis).
Show the code
# car::durbinWatsonTest(regbs)
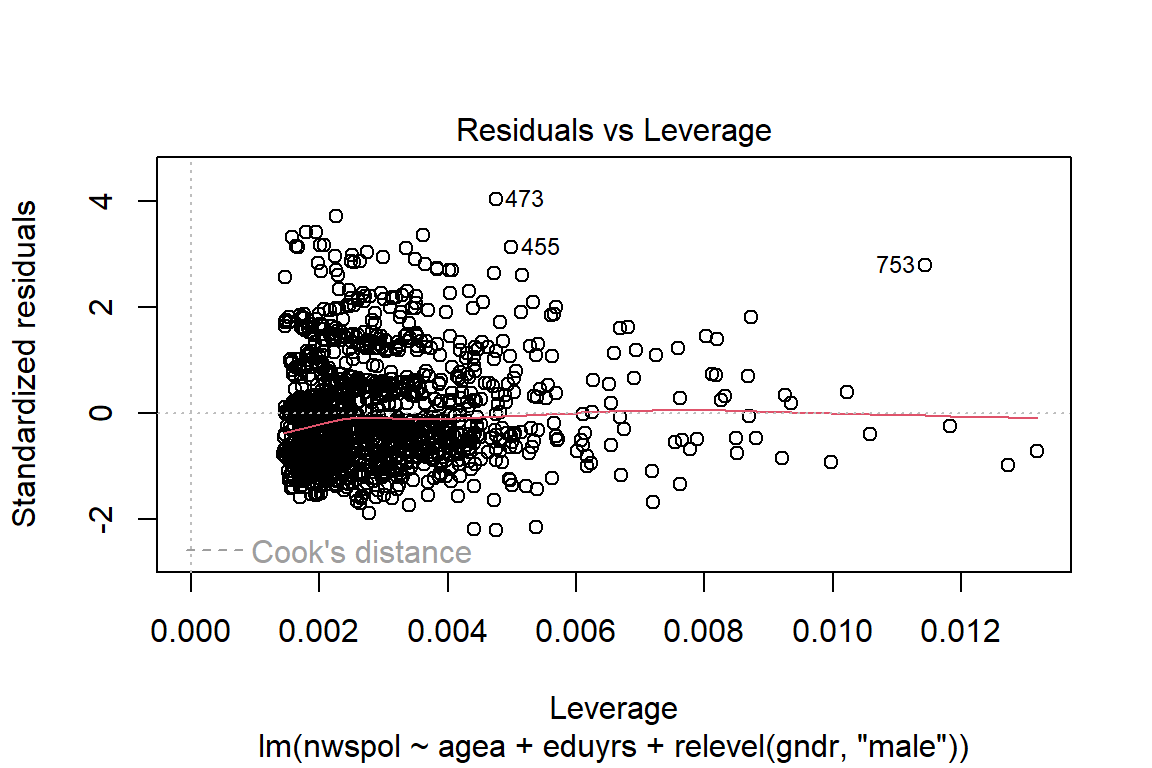
Fourth, we can also verify if we have outliers. A value \(>2(p+1)/n\) indicates an observation with high leverage, where \(p\) is the number of predictors and \(n\) is the number of observations (in our case: 2*(3+1)/1348=0.006).
Show the code
plot(regbs, 5)
To extract outliers, you might want to flag observations whose leverage score is more than three times greater than the mean leverage value as a high leverage point.
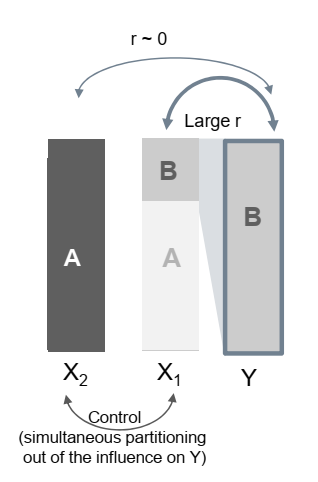
Suppose a new variable X2 is added to the regression equation in addition to X1. Suppose, X1 explains substantial variance of Y because both variables capture well a certain phenomenon (here: B). Under which circumstances does this increase the model quality (\(R^2\))?
Normally, an increase in \(R^2\) can only be expected if:
X2 is correlated with Y: when both X2 and Y capture a particular phenomenon (here: C)
X1 and X2 are only weakly correlated because they predominantly capture different phenomena (here: B and C)
In cases where this ideal scenario is not or only limited valid, R2 will hardly increase, and may even weaken the influence of X1 on Y when X2 is added.
Now, suppose a predictor variable X1 captures 70% of phenomenon A and 30% of another phenomenon B. Y, on the other hand, captures phenomenon B dominantly. Then the variable X1 will correlate only very moderately with Y since the dominance of phenomenon B in Y has virtually prevented a higher correlation. Suppose a new variable X2 is added to the regression equation. Under what circumstances does this increase the model quality?
Response: suppressor effect
Assume that a second predictor variable X2 also dominantly captures phenomenon A. Phenomenon B is only weakly or not at all captured in X2. Since the predictors are controlled simultaneously and reciprocally, the influence of the first predictor variable X1 is “freed” from the dominant influence of phenomenon A and suddenly phenomenon B dominates, which in turn is also dominant in Y. Suddenly there is a strong influence of the predictor variable X1 on Y! In this case the second variable X2 is suppressor for the influence of X1 on Y. Why? Only the residual variance of X1 remains for correlations with Y, but this has very large common variance components with Y.