11.1 Recap on factor analysis: exploratory and confirmatory
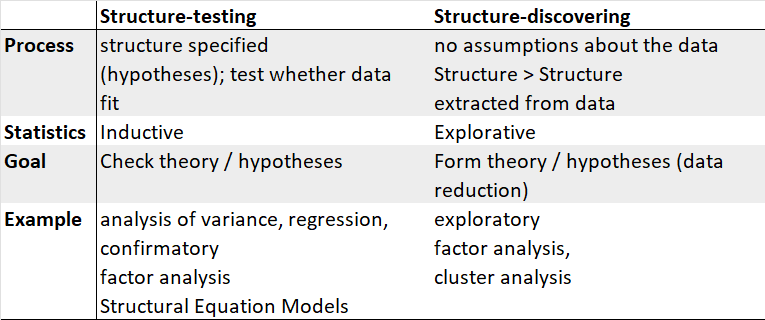
In exploratory factor analysis (EFA), all measured variables are related to every latent variable. It is used to reduce data to a smaller set of summary variables and to explore the underlying theoretical structure of the phenomena. It asks what factors are given in observed data and, thereby, requires interpretation of usefulness of a model (it should be confirmed with confirmatory factor analysis).
In confirmatory factor analysis (CFA), researchers can specify the number of factors required in the data and which measured variable is related to which latent variable. It asks how well a proposed model fits a given data.
The differences in both approaches can be summarized as follows:
11.1.1 Prerequisites
Prerequisites of factor analysis include:
Condition: There are several interval-scaled characteristics (items).
Rule of thumb: At least 50 people and 3x more people as variables (ideally: 5x more people as variables!).
We will use a real world example of a questionnaire which Andy Field terms the SPSS Anxiety Questionnaire (SAQ). The first eight items consist of the following:
Statistics makes me cry
My friends will think I’m stupid for not being able to cope with SPSS
Standard deviations excite me
I dream that Pearson is attacking me with correlation coefficients
The interpretation of the correlation table are the standardized covariances between a pair of items. In a correlation table, the diagonal elements are always one because an item is always perfectly correlated with itself.
In a typical variance-covariance matrix, the diagonals constitute the variances of the item and the off-diagonals the covariances.
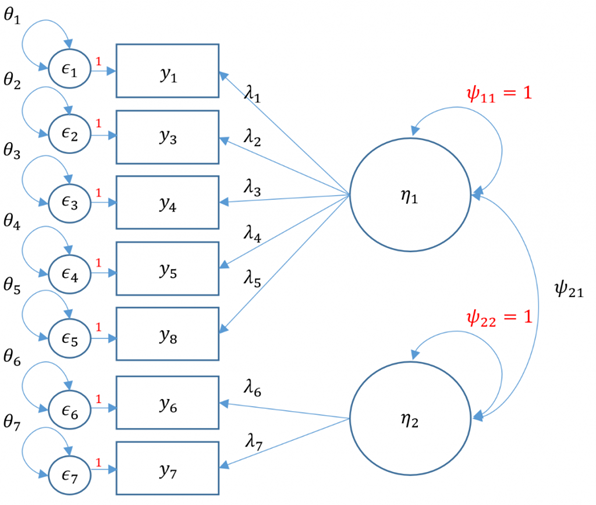
We decide the use only Items 1, 3, 4, 5, and 8 as indicators of SPSS Anxiety and Items 6 and 7 as indicators of Attribution Bias. Thus, we will now proceed with a two-factor CFA where we assume uncorrelated (or orthogonal) factors. Having a two-item factor presents a special problem for identification. In order to identify a two-item factor there are two options:
Freely estimate the loadings of the two items on the same factor but equate them to be equal while setting the variance of the factor at 1
Freely estimate the variance of the factor, using the marker method for the first item, but covary (correlate) the two-item factor with another factor
Since we are doing an uncorrelated two-factor solution here, we are relegated to the first option.
How does this model compare to a one-factor model?
Show the code
library(lavaan)# one factor modelm1 <-'f1 =~ q01+ q03 + q04 + q05 + q08 f2 =~ a*q06 + a*q07 f1 ~~ 0*f2 'onefac7items <-cfa(m1, data=dat, std.lv=TRUE) summary(onefac7items, fit.measures=TRUE, standardized=TRUE)## lavaan 0.6.17 ended normally after 14 iterations## ## Estimator ML## Optimization method NLMINB## Number of model parameters 14## Number of equality constraints 1## ## Number of observations 2571## ## Model Test User Model:## ## Test statistic 841.205## Degrees of freedom 15## P-value (Chi-square) 0.000## ## Model Test Baseline Model:## ## Test statistic 3876.345## Degrees of freedom 21## P-value 0.000## ## User Model versus Baseline Model:## ## Comparative Fit Index (CFI) 0.786## Tucker-Lewis Index (TLI) 0.700## ## Loglikelihood and Information Criteria:## ## Loglikelihood user model (H0) -23684.164## Loglikelihood unrestricted model (H1) -23263.562## ## Akaike (AIC) 47394.328## Bayesian (BIC) 47470.405## Sample-size adjusted Bayesian (SABIC) 47429.101## ## Root Mean Square Error of Approximation:## ## RMSEA 0.146## 90 Percent confidence interval - lower 0.138## 90 Percent confidence interval - upper 0.155## P-value H_0: RMSEA <= 0.050 0.000## P-value H_0: RMSEA >= 0.080 1.000## ## Standardized Root Mean Square Residual:## ## SRMR 0.180## ## Parameter Estimates:## ## Standard errors Standard## Information Expected## Information saturated (h1) model Structured## ## Latent Variables:## Estimate Std.Err z-value P(>|z|) Std.lv Std.all## f1 =~ ## q01 0.539 0.017 31.135 0.000 0.539 0.651## q03 -0.573 0.023 -24.902 0.000 -0.573 -0.533## q04 0.652 0.020 33.032 0.000 0.652 0.687## q05 0.567 0.020 27.812 0.000 0.567 0.588## q08 0.431 0.019 22.862 0.000 0.431 0.494## f2 =~ ## q06 (a) 0.797 0.017 46.329 0.000 0.797 0.710## q07 (a) 0.797 0.017 46.329 0.000 0.797 0.723## ## Covariances:## Estimate Std.Err z-value P(>|z|) Std.lv Std.all## f1 ~~ ## f2 0.000 0.000 0.000## ## Variances:## Estimate Std.Err z-value P(>|z|) Std.lv Std.all## .q01 0.395 0.015 26.280 0.000 0.395 0.576## .q03 0.827 0.027 30.787 0.000 0.827 0.716## .q04 0.474 0.020 24.230 0.000 0.474 0.527## .q05 0.608 0.021 29.043 0.000 0.608 0.654## .q08 0.575 0.018 31.760 0.000 0.575 0.756## .q06 0.623 0.027 22.916 0.000 0.623 0.495## .q07 0.580 0.026 21.925 0.000 0.580 0.477## f1 1.000 1.000 1.000## f2 1.000 1.000 1.000#uncorrelated two factor solution, var std methodm <-'f1 =~ q01+ q03 + q04 + q05 + q08 f2 =~ a*q06 + a*q07 f1 ~~ 0*f2 'twofac7items <-cfa(m, data=dat, std.lv=TRUE) summary(twofac7items, fit.measures=TRUE, standardized=TRUE)## lavaan 0.6.17 ended normally after 14 iterations## ## Estimator ML## Optimization method NLMINB## Number of model parameters 14## Number of equality constraints 1## ## Number of observations 2571## ## Model Test User Model:## ## Test statistic 841.205## Degrees of freedom 15## P-value (Chi-square) 0.000## ## Model Test Baseline Model:## ## Test statistic 3876.345## Degrees of freedom 21## P-value 0.000## ## User Model versus Baseline Model:## ## Comparative Fit Index (CFI) 0.786## Tucker-Lewis Index (TLI) 0.700## ## Loglikelihood and Information Criteria:## ## Loglikelihood user model (H0) -23684.164## Loglikelihood unrestricted model (H1) -23263.562## ## Akaike (AIC) 47394.328## Bayesian (BIC) 47470.405## Sample-size adjusted Bayesian (SABIC) 47429.101## ## Root Mean Square Error of Approximation:## ## RMSEA 0.146## 90 Percent confidence interval - lower 0.138## 90 Percent confidence interval - upper 0.155## P-value H_0: RMSEA <= 0.050 0.000## P-value H_0: RMSEA >= 0.080 1.000## ## Standardized Root Mean Square Residual:## ## SRMR 0.180## ## Parameter Estimates:## ## Standard errors Standard## Information Expected## Information saturated (h1) model Structured## ## Latent Variables:## Estimate Std.Err z-value P(>|z|) Std.lv Std.all## f1 =~ ## q01 0.539 0.017 31.135 0.000 0.539 0.651## q03 -0.573 0.023 -24.902 0.000 -0.573 -0.533## q04 0.652 0.020 33.032 0.000 0.652 0.687## q05 0.567 0.020 27.812 0.000 0.567 0.588## q08 0.431 0.019 22.862 0.000 0.431 0.494## f2 =~ ## q06 (a) 0.797 0.017 46.329 0.000 0.797 0.710## q07 (a) 0.797 0.017 46.329 0.000 0.797 0.723## ## Covariances:## Estimate Std.Err z-value P(>|z|) Std.lv Std.all## f1 ~~ ## f2 0.000 0.000 0.000## ## Variances:## Estimate Std.Err z-value P(>|z|) Std.lv Std.all## .q01 0.395 0.015 26.280 0.000 0.395 0.576## .q03 0.827 0.027 30.787 0.000 0.827 0.716## .q04 0.474 0.020 24.230 0.000 0.474 0.527## .q05 0.608 0.021 29.043 0.000 0.608 0.654## .q08 0.575 0.018 31.760 0.000 0.575 0.756## .q06 0.623 0.027 22.916 0.000 0.623 0.495## .q07 0.580 0.026 21.925 0.000 0.580 0.477## f1 1.000 1.000 1.000## f2 1.000 1.000 1.000
Interpretation
Since we have 7 items, the total elements in our variance covariance matrix is 7(7+1)/2=28. The number of free parameters to be estimated include 7 residual variances , 7 loadings for a total of 14. Then we have 28-14=14 degrees of freedom. However for identification of the two indicator factor model, we constrained the loadings of Item 6 and Item 7 to be equal, which frees up a parameter and hence we end up with 14+1=15 degrees of freedom.
We can see that the uncorrelated two factor CFA solution gives us a higher chi-square (lower is better), higher RMSEA and lower CFI/TLI than the one-factor model, which means overall it is a poorer fitting model.
We decide to go with a correlated (oblique) two factor model:
Show the code
#correlated two factor solution, marker methodm <-'f1 =~ q01+ q03 + q04 + q05 + q08 f2 =~ q06 + q07'twofac7items_n <-cfa(m, data=dat, std.lv=TRUE) summary(twofac7items_n, fit.measures=TRUE, standardized=TRUE)## lavaan 0.6.17 ended normally after 18 iterations## ## Estimator ML## Optimization method NLMINB## Number of model parameters 15## ## Number of observations 2571## ## Model Test User Model:## ## Test statistic 66.768## Degrees of freedom 13## P-value (Chi-square) 0.000## ## Model Test Baseline Model:## ## Test statistic 3876.345## Degrees of freedom 21## P-value 0.000## ## User Model versus Baseline Model:## ## Comparative Fit Index (CFI) 0.986## Tucker-Lewis Index (TLI) 0.977## ## Loglikelihood and Information Criteria:## ## Loglikelihood user model (H0) -23296.945## Loglikelihood unrestricted model (H1) -23263.562## ## Akaike (AIC) 46623.891## Bayesian (BIC) 46711.672## Sample-size adjusted Bayesian (SABIC) 46664.013## ## Root Mean Square Error of Approximation:## ## RMSEA 0.040## 90 Percent confidence interval - lower 0.031## 90 Percent confidence interval - upper 0.050## P-value H_0: RMSEA <= 0.050 0.952## P-value H_0: RMSEA >= 0.080 0.000## ## Standardized Root Mean Square Residual:## ## SRMR 0.021## ## Parameter Estimates:## ## Standard errors Standard## Information Expected## Information saturated (h1) model Structured## ## Latent Variables:## Estimate Std.Err z-value P(>|z|) Std.lv Std.all## f1 =~ ## q01 0.513 0.017 30.460 0.000 0.513 0.619## q03 -0.599 0.022 -26.941 0.000 -0.599 -0.557## q04 0.658 0.019 34.876 0.000 0.658 0.694## q05 0.567 0.020 28.676 0.000 0.567 0.588## q08 0.435 0.018 23.701 0.000 0.435 0.498## f2 =~ ## q06 0.669 0.025 27.001 0.000 0.669 0.596## q07 0.949 0.027 35.310 0.000 0.949 0.861## ## Covariances:## Estimate Std.Err z-value P(>|z|) Std.lv Std.all## f1 ~~ ## f2 0.676 0.020 33.023 0.000 0.676 0.676## ## Variances:## Estimate Std.Err z-value P(>|z|) Std.lv Std.all## .q01 0.423 0.014 29.157 0.000 0.423 0.617## .q03 0.796 0.026 31.025 0.000 0.796 0.689## .q04 0.466 0.018 25.824 0.000 0.466 0.518## .q05 0.608 0.020 30.173 0.000 0.608 0.654## .q08 0.572 0.018 32.332 0.000 0.572 0.752## .q06 0.811 0.030 27.187 0.000 0.811 0.644## .q07 0.314 0.040 7.815 0.000 0.314 0.258## f1 1.000 1.000 1.000## f2 1.000 1.000 1.000
Interpretation
Compared to the uncorrelated two-factor solution, the chi-square and RMSEA are both lower. The test of RMSEA is not significant which means that we do not reject the null hypothesis that the RMSEA is less than or equal to 0.05. Additionally the CFI and TLI are both higher and pass the 0.95 threshold. This is even better fitting than the one-factor solution. We then choose the final two correlated factor CFA model as shown below: