Many research topics have multilevel structured data which consist of multiple macro and micro units within each macro unit (e.g. individuals within countries, individuals within occupations, children within classes within schools, etc). Therefore, at each level there are both mean characteristics (fixed effects) and differences (random effects).
Single level regression modelling is not the appropriate method to use here. For instance, the effect of an X within clusters can be different from the effect between clusters. Indeed, single level regression does not consider the nested data structure, which may violate the uncorrelated errors assumption. It is likely that in a “rich” country all people have higher wages than in “poor” countries? If errors are correlated, this is likely to cause the following problems:
efficiency of estimators is low
standard errors are low
coefficients are often significant
It will also be unclear:
how much variation in Y is at each level?
how much the context impacts on individual level after controlling for other relevant factors?
The purpose of multilevel modelling (MLM) is to correct for biased estimates resulting from clustering and to provide correct standard errors, confidence intervals, as well as significance tests. It will thus decompose the total variance of Y into portions associated with each level (e.g. individual vs country).
We might want to know: How much variation is there in individual wages between and within countries? Which countries have particularly low and high wages ?
13.1.1 Fixed versus random effects
In order to understand MLM we need to understand random effects, and to understand random effects we need to understand variance. We often need to think more about where the variance in our system is showing up in our model. It allows us to decompose the variance of the dependent variable into:
within-context variance
between-context variance
So far, we are familiar with the residual variance from OLS, but might that residual variance be better attributed to within a group? Or between a group?
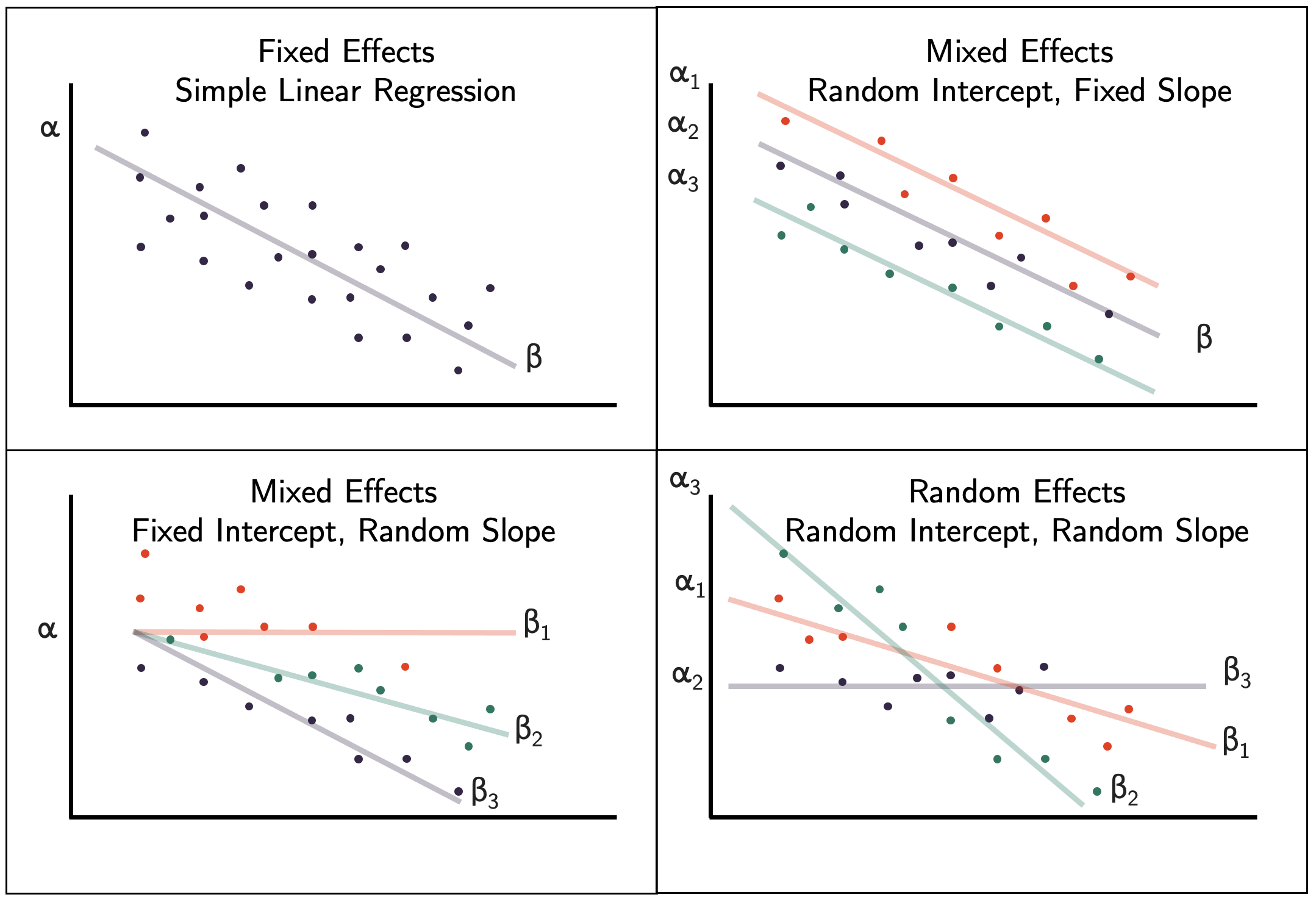
Recall that a factor is a categorical predictor that has two or more levels. Up to this point (e.g. in ANOVAs) we have only talked about fixed factors which assumes that the levels are separate, independent, and not similar. Fixed effects estimate separate levels with no relationship assumed between the levels. Fixed effects also assume a common variance known as homoscedasticity. Post-hoc adjustments are needed to do pairwise comparisons of the different factor levels. Random effects means that each level can be thought of as a random variable from an underlying process or distribution. Estimation of random effects provides inference about the specific levels (similar to a fixed effect), but also population level information (think about it as if each level of the effect is a draw from a random variable).
13.1.2 Example
Let’s image that we have 10 people (10 levels in our model) in a study about time spent to read the news on a daily basis over a 5-day period. Each day, we ask people to report how much time they spent reading the news (n=10*5=50) so that each person has 5 observations.
A fixed effect model enables us to estimate the means of the 10 individuals and assumes that each of the individuals has a common variance around their news reading time (variance is the same or similar for everyone in the study).
A random effect model enables us to estimate the mean and variance of the participants and to make a reasonable prediction about others that were not enrolled in the study (amount of time spent to read the news within a given individual is much likely to be similar than compared to someone else).
13.1.3 When not to use random effects
You might not want to use random effects when the number of factor levels is very low (there is not definitive recommendation here). Furthermore, it is commonly reported that you may want five or more factor levels for a random effect in order to really benefit from what the random effect can do. Note that a group with a large sample size and/or strong information (e.g. a strong relationship) will have very little influence of the grand mean and largely reflect the information contained entirely within the group.
Another case in which you may not want to random effect is when you do not assume that your factor levels come from a common distribution.
We already know about the OLS model (labelled “fixed effects” in the figure below). The next figure displays different types of random effects:
One might account for the nested structured of the data by including a “grouping variable” for individuals (dummy for each country or year) or inclusion of contextual explanatory variables (e.g. gender equality index per country).
\[y_{ij}=\beta_0 + \beta_1*X_{ij} + \sum^{}_{C-1}(\beta_C*CD_j + \epsilon_{ij})\] where, \(\beta_0\) is the overall intercept (e.g. reference country or year) and \(\beta_C\) is the intercept for one country. The problem is that grouping parameters are treated as fixed effects ignoring random variability associated with macro-level characteristics. This “dummy variable approach” thus suggests that group differences are fixed effects. What if number of groups is very large? What about including group-level predictors as all degrees of freedom at group-level have been consumed by country dummy?
13.3 Random intercept model (with fixed slope)
The next model we will examine is the MLM with a random intercept and fixed slope.
13.3.1 Null model
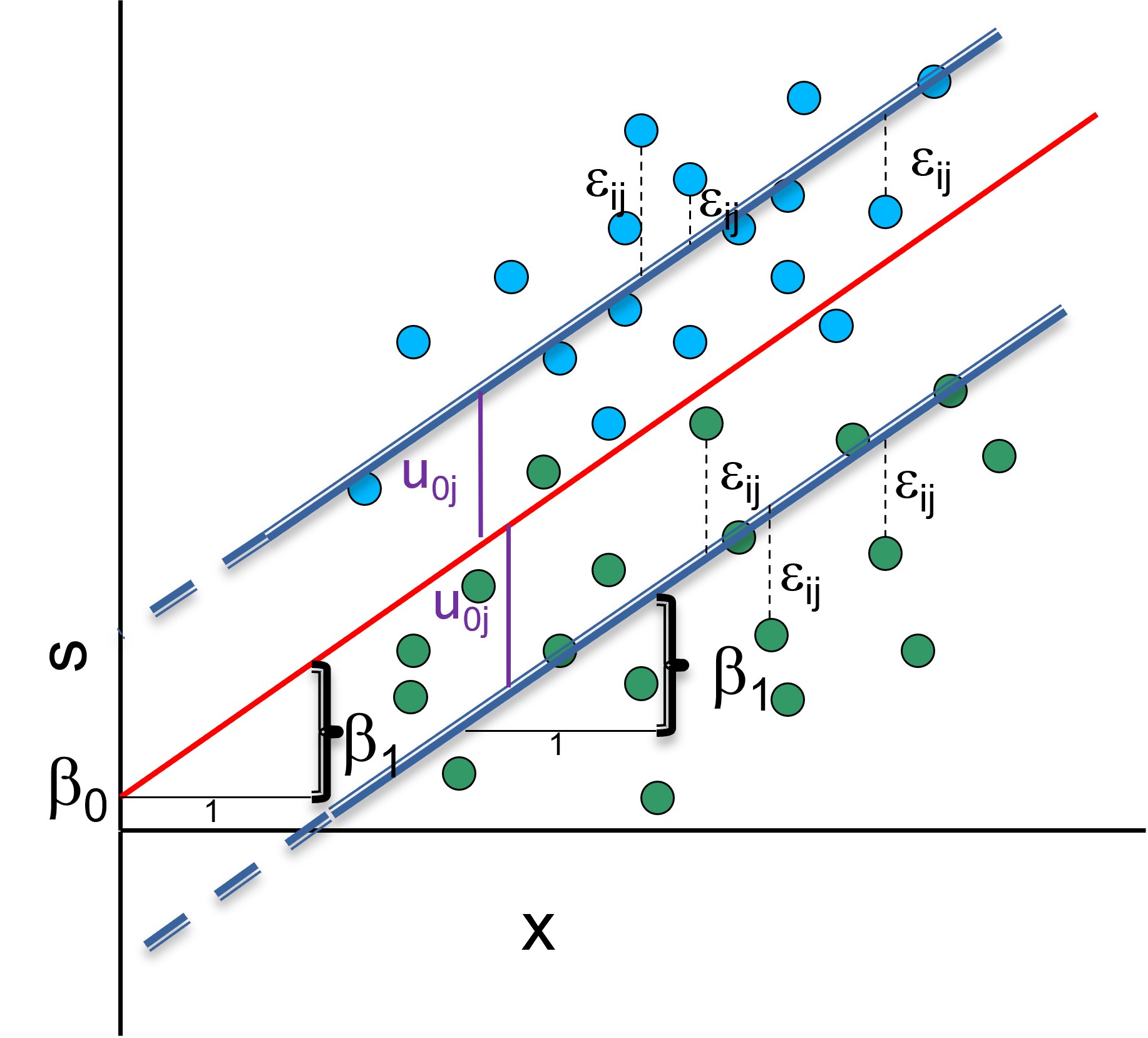
In its simplest form, a MLM is in the form of a “null model” which contains no explanatory variables. It thus includes one regression constant (intercept) and assumes that this varies across contexts. The intercept is a random variable.
So far, we are able to answer questions like: Are there countries differences with respect to happiness? How much of this variation is due to these country differences?
13.3.2 Interclass Correlation Coefficient (ICC)
A MLM with a random intercept is a point where we can pause and run a diagnostic called the Interclass Correlation Coefficient (ICC).
\[ICC = \frac{\sigma^2_\alpha}{\sigma^2+\sigma^2_\alpha}\] The ICC tells us how much similarity is within contexts (i.e. countries). Basically, it accounts for the closeness of observations in same context relative to closeness of observations in different contexts.
For instance, it can tell us how much % of variance in Y (e.g. happiness) can be explained by context (belonging to a different country).
The ICC ranges from 0 (no clustering/single level data structure) and 1 (maximum clustering). In practice, 0 or 1 rarely occur. A general recommendation is that if the ICC is small, then use of a single level model.
13.3.3 Random intercept model (with fixed slope) including one predictor
At this stage, it is unclear which factors account for the variation. Are there more reasons why individuals and countries might differ with respect to happiness?
Random intercept model is a combination of variance component and a linear model (for a person \(i\) in country \(j\)). We thus have a fixed part (\(\beta_0 + \beta_x*X_{ij}\)), where the estimated parameters are the beta coefficients and are the same for each observation in the sample. We also have a random part (\(u_{0j} + \epsilon_{ij}\)), where estimated parameters are variances which are allowed to vary (e.g. across countries).
\[y_{ij}=\beta_0 + \beta_x*X_{ij} + u_{0j} + \epsilon_{ij}\] In this model, there are two random terms and therefore two types of residuals: \(u_j\) a the level-2 and \(e_{ij}\) at the level-1. There are also an overall (average) line \(β_0\) and group (average) lines \(β_0+u_j\).
So far, we are able to answer questions as: Do country differences in happiness remain after controlling for gender? How much of variation in happiness is due to country differences after controlling for gender? What is the relationship between an individual’s happiness and their gender?
13.3.4 Model assumptions
The model assumptions are that individual and group-level residuals are normally distributed. Furthermore, residuals at the same/different level are uncorrelated.
13.4 Random slope model (with random intercept)
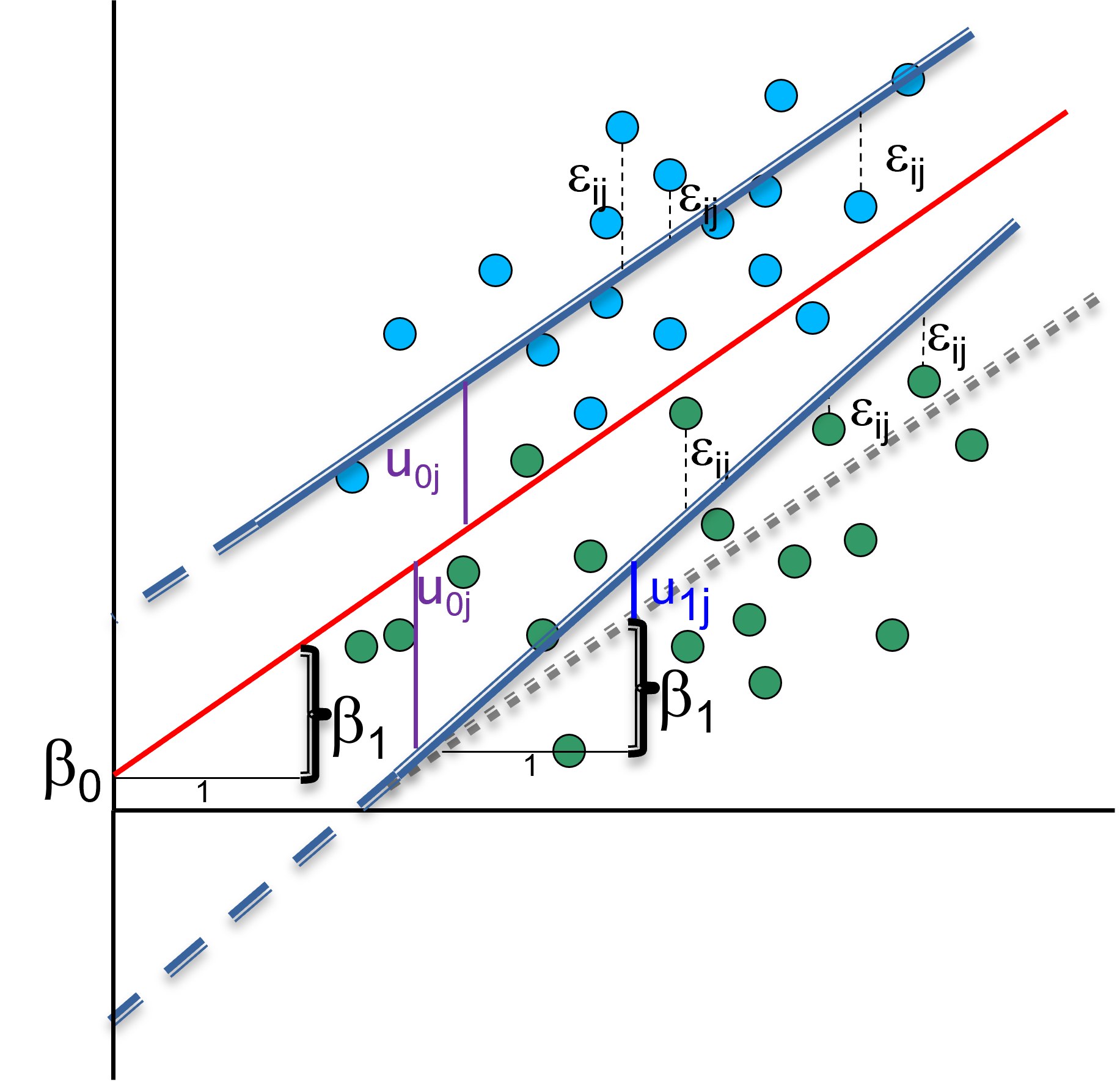
The assumption of random intercept model suggests that group lines have all same slope as overall regression line in every group (effect of X on Y is the same for every country). Is this always valid? It can be argued that X is not a fixed but a random effect and that its slope can vary across groups.
We can account for the random slope by adding random term to coefficient of \(x_{1ij}\) (e.g. working hours), so it can be different for each group (e.g. country):
\[ y_{ij} = \beta_0 + (\beta_1 + u_{1j})*x_{1ij} + u_{0j} + \epsilon_{0ij} \] Note that one extra parameter \(u_{1ij}\) leads to two extra parameters \(\sigma^2_{u1}\) (variance in slopes between groups) and \(\sigma^2_{u01}\) (covariance between intercepts and slopes).
With a random slope model, we could now answer questions as: Does the effect of being employed has the same impact on happiness across countries?
Useful reference:
Sommet, N. & Morselli, D. (2021). Keep Calm and Learn Multilevel Linear Modeling: A Three-Step Procedure Using SPSS, Stata, R, and Mplus. (International Review of Social Psychology), 34(1). Available here.
13.4.1 Note on fixed intercept with random slope model
It might be the case that a model requires a fixed intercept but a random slope specification. This could be the case when we hypothesize that the effect of our predictor differs among groups, but when we want to fix the intercept because we know that all groups start in a similar place.
13.4.2 Testing the random part
The likelihood ratio test (LRtest) can be used to compare the random slope model to a random intercept model. The null hypothesis states that \(\sigma^2_{u1}\) and \(\sigma^2_{u0}\) should equal 0. If this is true, the random intercept model is more appropriate than a random slope model. If random intercept/slope coefficients are not significantly different from zero, this suggests that there is not much random variability in the slope/intercept. Therefore, there is no need to specify random parameter.
13.5 Cross-level interactions
Adding cross-level interactions allows us to assess whether contextual factors (Z) influence the effect of level-1 X variables. For instance, we can answer questions such as: Is the effect of gender on happiness stronger/weaker in countries with a high gender equality index?
\[ y_{ij} = \beta_0 + \beta_1*x_{ij} + \beta_2*Z_j + \beta_3x_{ij}*Z_j + u_{0j} + u_{1j}x_{ij} + \epsilon_{ij} \] The cross-level interaction should be included in the fixed part of model. Therefore, the direct main and interaction effects have to be interpreted together (similar to OLS): the \(\beta_3\) coefficient indicates the impact of each unit change in Z on the slope \(\beta_1\).
Useful links to external data sources to link at the macro-level are:
To assess how much variance is explained by a model, simple OLS regression entail the \(R^2\) statistic (proportion of explained variance). In MLM, there are several several (co)variances.
Hox (2010, pp.70) proposes to examine residual error variance in a sequence of models. This approach suggests examining the residual error variances in a sequence of models:
intercept-only model (since there are no explanatory variables in the model, it is reasonable to interpret variances as the error variances)
model including the level-1 predictors
model including the level-2 predictors
model with random coefficient
model with cross-level interaction
Other useful references:
Clarke, P., Crawford, C., Steele, F. & Vignoles, A. (2010). The choice between fixed and random effects models: some considerations for educational research. Institute of Education DoQSS, Working Paper No. 10. Available here.
Moehring, K. (2012). The fixed effect as an alternative to multilevel analysis for cross-national analyses. GK Soclife working paper. Available here
13.7 Centering and standardizing
The regression intercept equals the expected value of Y if all X are 0. However, what if 0 has no useful meaning or is not possible? (e.g. age of 0). In this case, it is useful to transform the X variables, for instance by centering them. There are two options:
Grand mean centering: computing variables as deviations from the overall mean (the constant in model reflects the mean of all cases)
Group mean centering: computing variables as deviation from the group mean (decomposes within vs. between effects)
13.8 Concluding remarks
Ultimately the application of MLM with fixed or random effects is done to capture more realism in the phenomenon we are seeking to describe with our model. While all models are to some degree incorrect, inaccurate estimation or pooling dissimilar information may extend the degree to which the model is inaccurate or misleading.
13.9 In a nutshell
Multilevel modelling (MLM) is used when data are nested (e.g., individuals within countries, students within schools). It accounts for structure, dependency, and clustering. MLM adds realism by modelling differences both within and between clusters. It avoids misleading inferences from pooled models and provides a richer, more accurate understanding of hierarchical data.
Nested data violate OLS assumptions (e.g., uncorrelated errors). MLM corrects bias, provides accurate standard errors, and decomposes variance into within- and between-group components. It answers: How much variation in Y is due to individuals vs. contexts?
Fixed vs. Random Effects:
Fixed Effects: Treat group differences as unique and unrelated; assume equal variances.
Random Effects: Treat groups as samples from a distribution; estimate group-specific variation and population-level patterns. Random effects are preferred when groups are many and assumed to come from a common distribution.
Fixed Effects Regression vs. MLM:
Using dummies for groups (fixed effects models) controls for group differences but: prevents inclusion of group-level variables and assumes no random variation across groups. MLM handles these issues more flexibly.
Types of models:
Random Intercept Models: Allow groups (e.g., countries) to differ in their baseline level of Y. Useful for computing the Intraclass Correlation Coefficient (ICC), which quantifies how much variance is due to grouping.
Random Slope Models: Allow the effect of X on Y to vary across groups. This adds variance in slopes and a covariance between slopes and intercepts. Answer questions like: Does the effect of X differ across contexts?
Cross-Level Interactions: Examine whether group-level characteristics (Z) change the strength of individual-level relationships (X on Y). Example: Does gender equality moderate the gender–happiness link?
Centering & Interpretation: Centering (grand-mean or group-mean) clarifies intercepts and decomposes within- vs. between-group effects. Particularly important when “zero” on predictors is meaningless.
Variance Decomposition: Unlike OLS and its single \(R^2\), MLM evaluates changes in multiple variance components across model stages (null, level-1 predictors, level-2 predictors, random slopes, cross-level interactions).
13.10 How it works in R?
See the lecture slides on MLM:
You can also download the PDF of the slides here:
13.11 Time to practice on your own
In the following example, we would like to assess cross-national differences in the gender gap in working time.
First thing you want is to download the data from the European Social Survey and select the variables: country information, working time, gender and additional explanatory variables (e.g. level of education, having children, etc). Then, you want to know how the variables are coded and to apply the necessary changes. You can also filter outliers (e.g. very high working hours).
From the output, we see that gender has a negative effect on working hours: since gndr is coded 1 = female, 0 = male, the coefficient of about -2.32 means that women work on average about 2.3 fewer hours per week than men, controlling for country.
We also note country differences: each country coefficient shows how its average working time differs from the reference country (the country that does not appear in the list of dummies) once gender is held constant.
The Multiple R-squared is 0.1014 (adjusted \(R^2\) 0.1002), which means that the model explains roughly 10% of the overall variance in working hours.
Third, you conduct a “null” model with only working hours. This allows you to assess how much variation in working hours can be attributed to individual differences and country differences.
The ICC (Intraclass Correlation Coefficient) can be interpreted as the proportion of the total variance in working hours that is attributable to differences between countries rather than between individuals within countries.
Here, the ICC is 0.092, so about 9% of the variance in working hours is due to country-level differences, while about 91% is due to individual-level differences within countries.
The intercept (about 38.7, rounded to ~39 hours) is the expected weekly working time for an “average” person in an “average” country in this random-intercept model.
Fourth, you can conduct a random intercept model with gender, and compare it with a random intercept with individual level variables (having children, years of education, etc.).
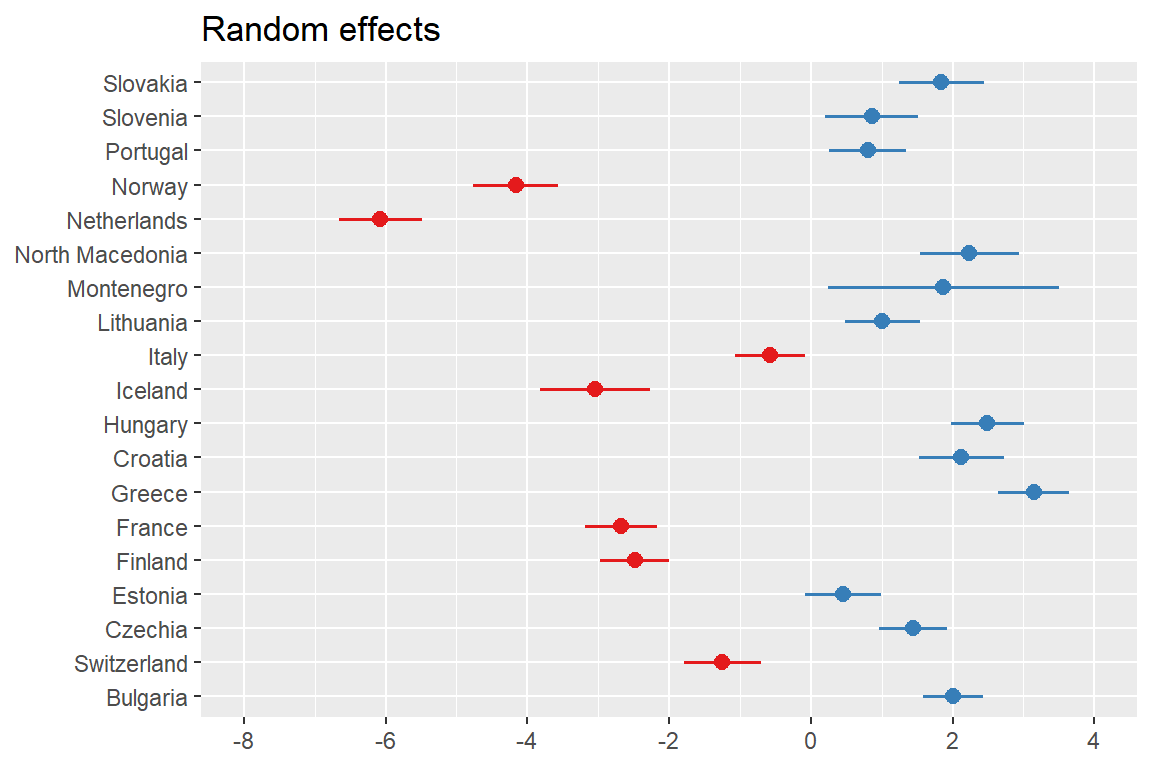
You can then visualize the country effect using sjPlot. The function produces a plot showing country-level deviations from the overall mean working hours in your random-intercept model (e.g., if the overall intercept = 39.9 hours and country A’s random effect is +1.8, then the predicted average for country A = 39.9 + 1.8 = 41.7 hours):
Show the code
sjPlot::plot_model(random, type ="re")
Interpretation
In the random-intercept model with gender only, the fixed intercept (about 39.9) means that the expected weekly working time for men (gndr = 0) in an “average” country is roughly 40 hours. The gender coefficient is about -2.32, so women work on average about 2.3 hours fewer than men, net of country differences.
The variance components show:
Between-country variance in the intercept: 6.78 (standard deviation 2.60 hours). So average working time differs between countries by about 2.5 hours on average.
When we add individual-level covariates (education and having children) in random2, the gender gap becomes slightly larger in absolute value (about -2.38), and:
eduyrs has a small negative effect (each additional year of education is associated with ~0.06 fewer hours worked per week on average).
chldhheNo is negative (-1.01), so individuals without children in the household work about 1 hour less per week than those with children, on average, controlling for other variables.
You can also test whether it makes sense to rely on a random intercept instead of the fixed effects model. In R, anova() for mixed models performs a likelihood-ratio test comparing two (approximately) nested models. It tests whether the more complex model (with more parameters) improves model fit sufficiently to justify the additional complexity.
The anova() output (here essentially a likelihood-ratio test, not a classical ANOVA in the one-way sense) compares how well the two models fit the data.
The random-intercept model actually has the higher log-likelihood and lower AIC compared to the fixed-effects model with country dummies (dummy_model).
Based on AIC and log-likelihood, it is the random-intercept model that provides thebetter fit to the data, not the fixed-effects model.
Fifth, we can conduct a random slope model with gender:
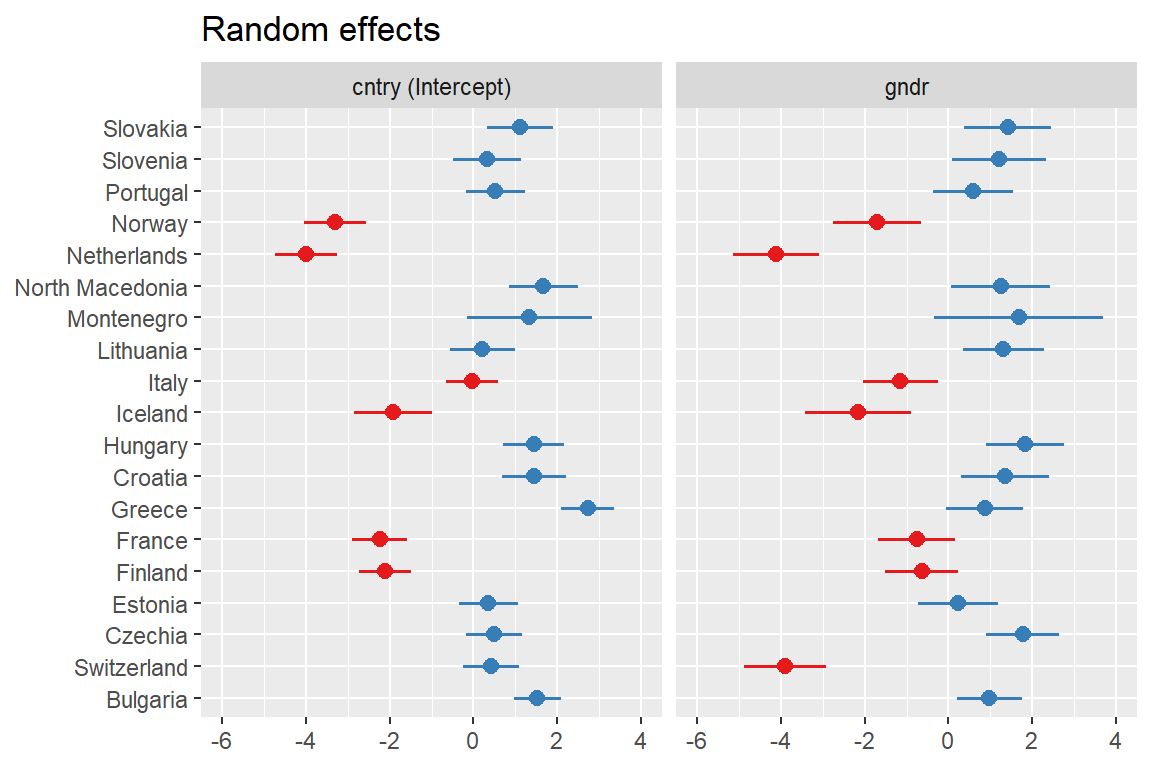
You can visualize the random effects using sjPlot. This plot estimates, for each country: i) a random intercept (how that country’s average working hours differ from the overall mean); ii) a random slope for gender (how the gender gap differs from the overall gender effect). Together, the two panels illustrate substantial cross-national variation in both overall working time and the magnitude of the gender gap:
Show the code
sjPlot::plot_model(randomslope, type ="re")
Interpretation
The fixed intercept (~39.8) again represents expected working hours for men (gndr = 0) in an “average” country. The fixed slope for gndr of about -2.32 means that, on average across countries, women work about 2.3 hours fewer per week than men.
The random effects tell us that both the average working time and the gender gap vary across countries:
Between-country variance in the intercept is 3.53, which corresponds to a standard deviation of about 1.88 hours. So average working hours differ between countries by roughly 2 hours around the overall mean.
Between-country variance in the gender effect is 3.75, SD about 1.94 hours. So the size of the gender gap in working hours differs between countries by about 2 hours on average.
The correlation between the country-specific intercepts and slopes is 0.64. A positive correlation means that in countries where people tend to work more hours on average, the gender difference in working hours (the slope for gndr) also tends to be less negative / more positive (i.e. the female–male gap is smaller or even reversed), and vice versa.
The residual variance (~64.13, SD 8.01) reflects within-country, person-level variation that is not captured by gender and the country-level random effects.
You can also test whether it makes sense to rely on a random slope instead of a fixed slope model.
The anova() output (here again using a likelihood-ratio test rather than a classical ANOVA) compares how well the two nested mixed-effects models fit the data.
The random-slope model, which allows the effect of gender to vary across countries, has a higher log-likelihood and lower AIC than the simpler random-intercept model.
The Chi-square statistic (162.52 with 2 degrees of freedom, p < 2.2e-16) indicates that the additional random-slope parameters lead to a significantly better fit compared to the model that only includes varying intercepts.
Thus, the random-slope specification provides a better description of the data than the random-intercept model alone.
Finally, you can add a cross-level interaction using the information provided by the Gender equality Index.
Here we allow both the gender effect and the Gender Equality Index (GEI) to influence working hours, and we include a cross-level interaction between GEI (country level) and gender (individual level).
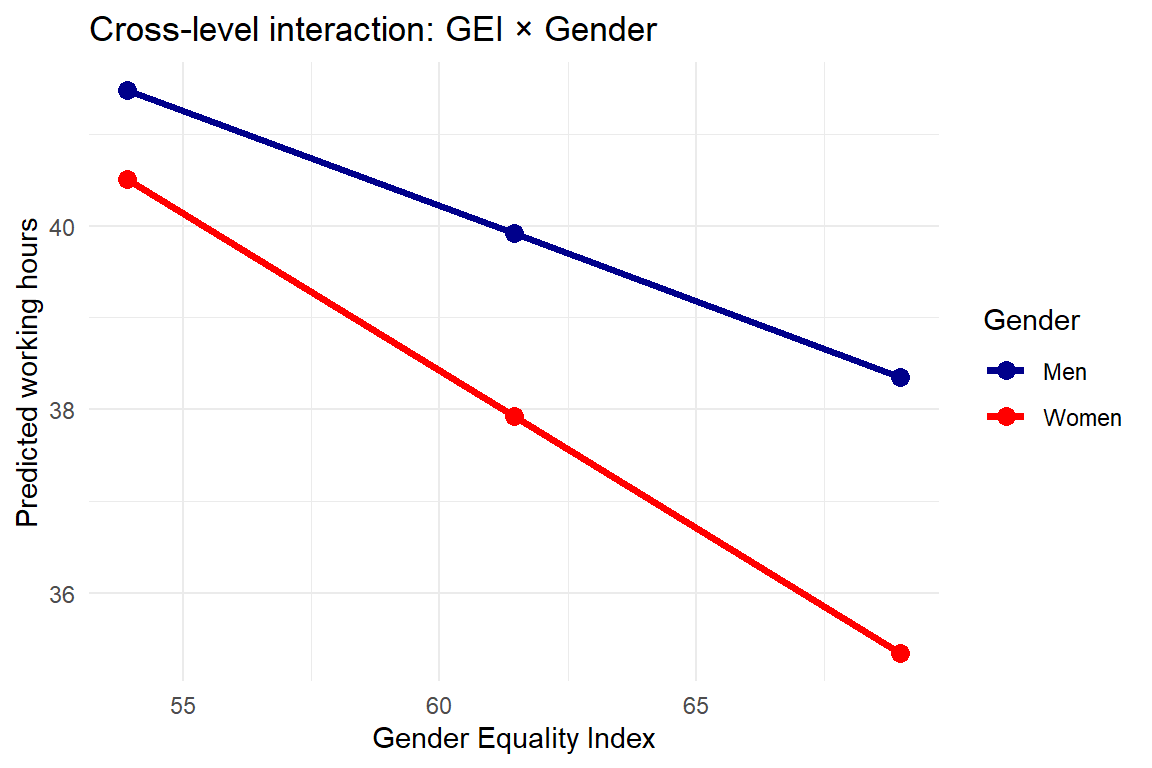
The coefficient for GEI (-0.208) tells us that, for men (gndr = 0), increasing GEI by 1 point is associated with about 0.21 fewer working hours per week. Higher gender equality correlates with slightly shorter working hours for men.
The interaction term gndr:GEI (-0.135) means that the effect of GEI on working hours is more negative for women than for men.
For women (gndr = 1), the slope of GEI is -0.208 − 0.135 = -0.343. So each additional GEI point is associated with about 0.34 fewer working hours for women.
This implies that as gender equality increases, women reduce their working hours more strongly than men, so the gender gap in working hours narrows.
Equivalently: the difference “women - men” in working hours changes by -0.135 hours for each one-point increase in GEI. So higher GEI is associated with a smaller gender gap in working time.
The intercept (52.7) is the expected working hours for men in a hypothetical country with GEI = 0; since actual GEI values are around 50–75, this intercept is not directly meaningful and would usually be made more interpretable by centering GEI (e.g., around its mean) before fitting the model.
Optionally, you can visualize the interaction effect:
The figure shows that in countries with higher gender equality, both men and women tend to work fewer hours. However, women’s working hours decline more sharply as GEI increases, resulting in a larger gender gap in more gender-equal societies. In other words, gender equality is associated with a widening rather than a narrowing of the disparity in paid working hours between men and women.