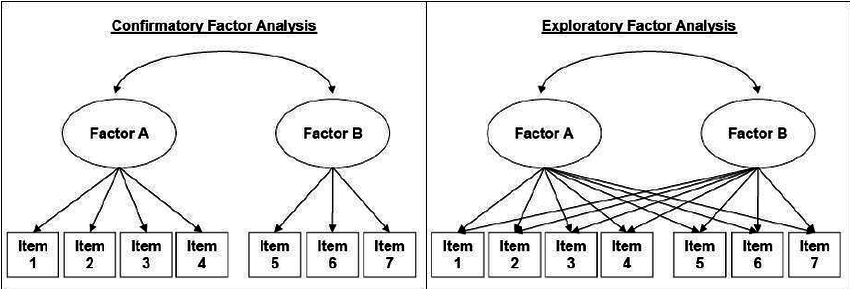
In exploratory factor analysis (EFA), all measured variables are related to every latent variable. It is used to reduce data to a smaller set of summary variables and to explore the underlying theoretical structure of the phenomena. It asks what factors are given in observed data and, thereby, requires interpretation of usefulness of a model (it should be confirmed with confirmatory factor analysis).
In confirmatory factor analysis (CFA), researchers can specify the number of factors required in the data and which measured variable is related to which latent variable. It asks how well a proposed model fits a given data. However, it does not give a definitive answer, but is rather useful to compare models (and data).
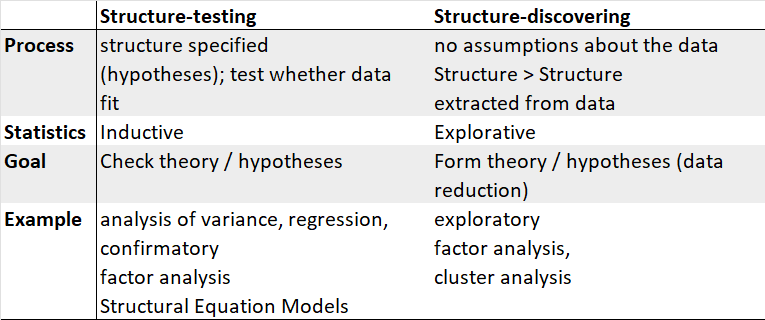
The differences in both approaches can be summarized as follows:
9.1.1 Prerequisites
Prerequisites of factor analysis include:
Condition: There are several interval-scaled characteristics (items).
Rule of thumb: At least 50 people and 3x more people as variables (ideally: 5x more people as variables!).
9.1.2 Dimensionality reduction
Dimensionality reduction transforms a data set from a high-dimensional space into a low-dimensional space, and can be a good choice when you suspect there are too many variables which can be a problem because it is difficult to understand (or visualize) data in higher dimensions.
Another potential consequence of having a multitude of predictors is possible harm to a model. The simplest example is a method like ordinary linear regression where the number of predictors should be less than the number of data points used to fit the model.
Another issue is multicollinearity, where between-predictor correlations can negatively impact the mathematical operations used to estimate a model. If there are an extremely large number of predictors, it is fairly unlikely that there are an equal number of real underlying effects. Predictors may be measuring the same latent effect(s), and thus such predictors will be highly correlated.
There are several dimensionality reduction methods that can be used with different types of data for different requirements:
combinating features:
linear: Principal component analysis (PCA), Factor analysis (FA), Multiple correspondence analysis (MCA), Linear discriminant analysis (LDA) or Singular value decomposition (SVD)
keeping most important features: Random forests, Forward or Backward selection
9.2 General procedure of EFA
Several steps need to be undertaken to conduct exploratorty factor analysis:
Setup and evaluate data set
Choose number of factors to extract
Extract (and rotate) factors
Evaluate what you have and possibly repeat the second and third steps
Interpret and write-up results
There are also general guidelines to follow:
It is better to select only the variables of interest from the data set.
As factor analysis (and PCA) does not play well with missing data, it is better to remove cases that have missing data.
Remember that factor analysis is designed for continuous data, although it is possible to include categorical data in a factor analysis.
9.3 Suitability of the data
Only relevant items may be included in the factor analysis. For instance, items must correlate significantly. Here, Bartlett Test is useful to assess the hypothesis that the sample came from a population in which the variables are uncorrelated. It checks whether the correlation matrix is an identity matrix or not:
H0: The variables are uncorrelated in the population.
H1: The variables are correlated in the population.
Kaiser-Meyer-Olkin criterion (KMO) and Measure of Sampling Adequacy (MSA) further test to what extent the variance of one variable is explained by the other variables. This indicates whether a data set is suitable for a factor analysis:
value range 0-1
values from .8 desirable
values below .5 unacceptable
9.4 PCA versus EFA
In Principal Component Analysis (PCA) each variable can be fully explained by a linear combination of r factors:
This approach should be used when data set structuring and data reduction is the primary goal.
In Exploratory Factor Analysis (EFA) each variable cannot be fully explained by a linear combination of r factors: e.g \[ Z_{ij} = f_{i1}a_{1j} + f_{i2}a_{2j} + ... + f_{ip}a_{pj} + e_j\]
This apporach should be used when trying to identify latent variables that are crucial to answering the items.
9.5 Spatial representation
Each of the given vectors (items) can be written exactly using the basis vectors (factors). The angle between the base vector (factor) and a given vector (item) is the correlation coefficient between item and factor: the factor loading.
Fundamental theorem: every observed value of a variable \(x_j\) can be described as a linear combination of several (hypothetical) factors (\(f_{jn}\)). That means that the answer to an item can be traced back to the sum of the factor values (\(f_{jn}\)), which are weighted with the factor loadings (\(a_{jn}\)).
9.6 Extraction of the factors
To extract the factors, we can z-standardize all variables (mean = 0, standard deviation = 1, variance = 1). The factor that explains the variance of all variables (\(x_1\) to \(x_j\)) at most is searched for step by step. Then - similar to multiple regression - a linear combination of the items is formed:
To measure the explanation of the variance of a variable, the coefficient of determination represents the square of the factor loading (see \(R^2\) in the regression). The first factor is the z-standardized variable for which the sum of the determination coefficients is maximum.
9.7 Decision about the number of factors
There are 4 decision aids to decide about the number of factors:
Kaiser criterion: significant factor explains more variance than any of the original variables and this criterion is fulfilled from an eigenvalue of 1 onwards
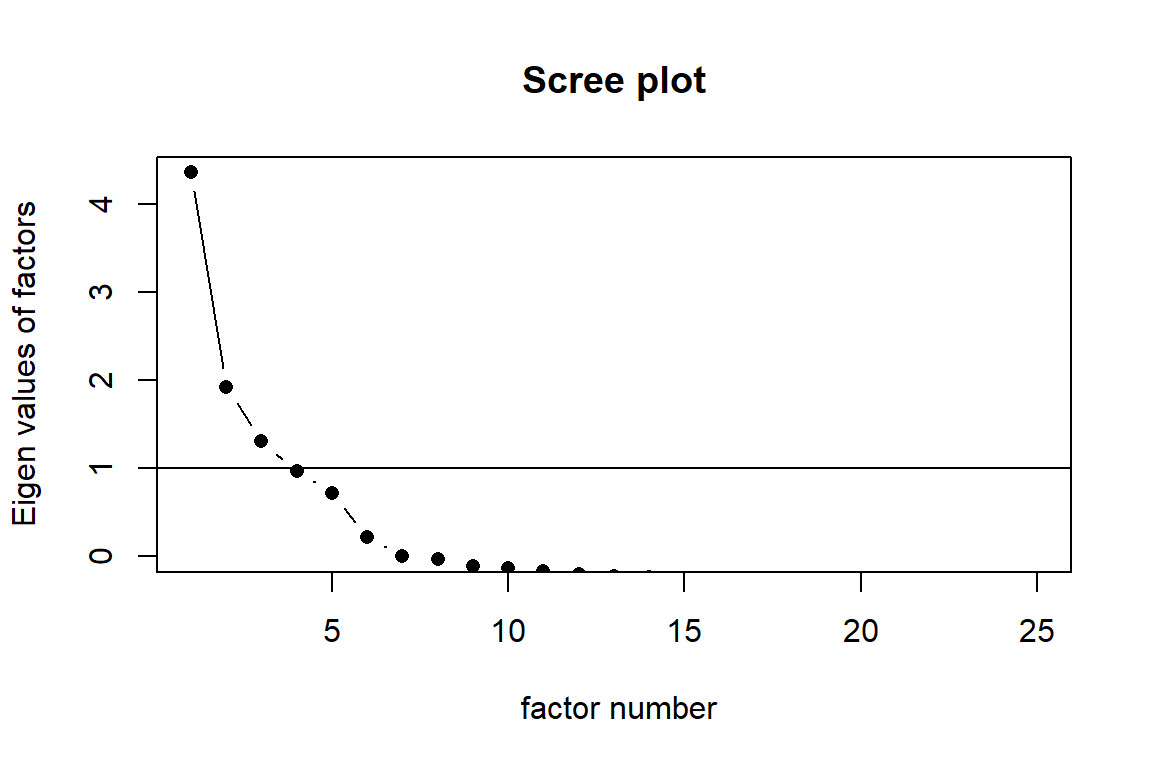
Scree plot: eigenvalues are plotted in the graphic and the factors that lie above a “threshold” are extracted
Content plausibility: so many factors are accepted that a plausible interpretation results
A priori criterion: it is theoretically determined in advance how many factors there should be
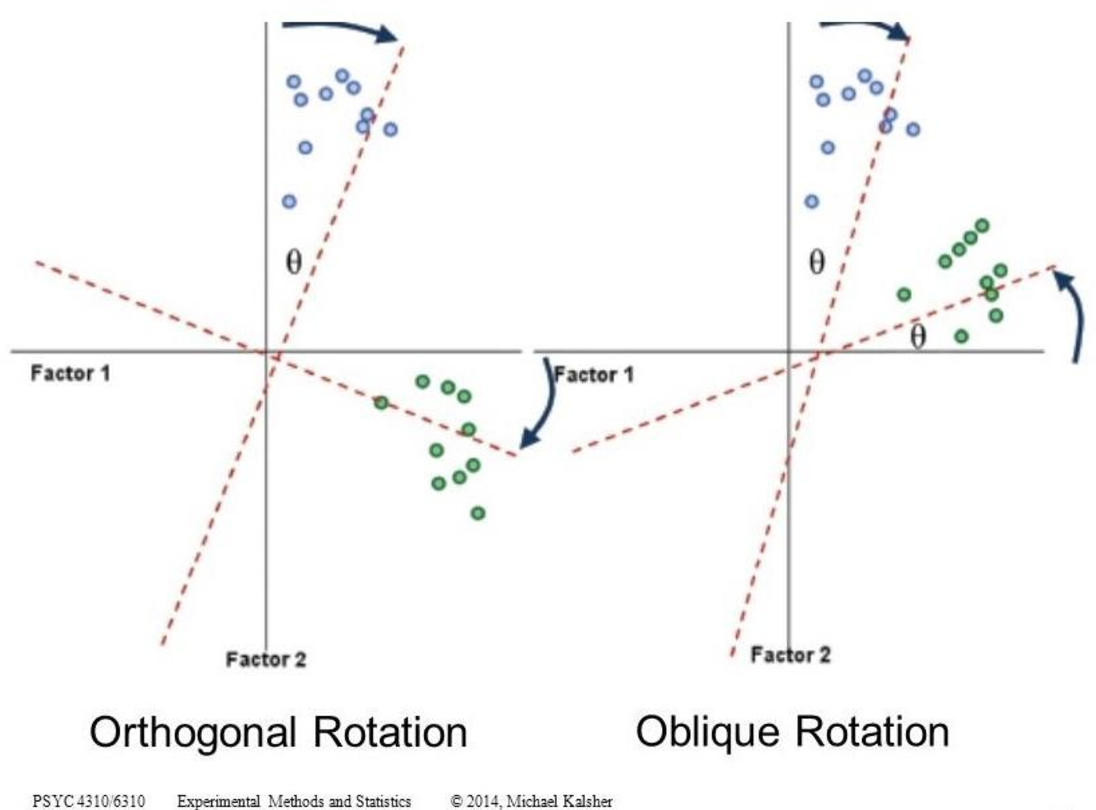
9.8 Factor rotation
By rotation one obtains simple structure, the factor interpretation is relieved. There are 2(3) types of rotation:
Varimax (Right Angle): the factor axes remain at right angles, so that they are uncorrelated
Oblique: the factor axes do not remain at right angles, so that they are correlated
Combination (first right angles and then oblique)
Which form of factor rotation is chosen in a specific case often depends on the theory behind it:
In the case of orthogonal rotations, the results are easier to interpret because the factors are uncorrelated.
Orthogonal rotations are usually also appropriate for pure dimension reduction.
However, orthogonal models often do not do justice to the underlying relationships:
The assumption of zero correlation between the factors is often too strict and does not reflect the complexity of the data.
If highly correlated factors are assumed in the data, an oblique rotation appears to make more sense than an orthogonal one.
9.9 Interpretation and naming
Factor interpretation is based on the factor loadings. Loadings from .5 are usually interpreted. Ideally, variables load exactly high on one factor and low on another.
For factor naming, variables with higher loadings should be given more consideration. A negative charge does not mean that the item does not belong to the factor. However, the sign must be taken into account in the interpretation.
Possible problems:
Loading several variables on several factors poses interpretation difficulties
Negative factor, or one-item factor
9.10 Lexicon
Factor: latent dimension “behind” the variables, which is responsible for the manifestation of a directly measured variable
Component: Collection of variables that have things in common
Indicator (Item): a directly measured variable that, together with other variables, makes up a component/factor
Factor loading: Correlation between a variable and a factor (should be > .5 on one factor and preferably <.3 on other factors)
Squared factor loadings: indicates the proportion of variance (=determination coefficient) of the variable that is explained by the factor
Eigenvalue of the factor: proportion of the variance of all directly measured variables that is explained by a factor (=sum of the squared factor loadings [column by column]). For a factor to be relevant enough to be extracted, its eigenvalue should be > 1
Commonality of a variable: proportion of the variance of an item that is explained by all factors (= sum of the squared factor loadings [row by row])
Factor value: calculated value based on the observed values on the measured variables and the factor loading of the variable on the factor
Rotation: optimization of the factor solution, perpendicular (orthogonal) vs oblique rotation
9.11 How it works in R?
See the lecture slides exploratory factor analysis:
You can also download the PDF of the slides here:
9.12 Quiz
True
False
Statement
The Kaiser’s criterion is a measure of whether the data is suitable for an exploratory factor analysis.
Both in EFA and CFA we specify the pattern of indicator-factor loadings a priori.
Bartlett Test is useful to assess whether the sample came from a population in which the variables are uncorrelated.
Kaiser’s criterion and scree plot are alternative methods for determining how many factors to retain.
My results will appear here
9.13 Example from the literature
The following article relies on EFA as a method of analysis:
Schulz, A., Müller, P., Schemer, C., Wirz, D. S., Wettstein, M., & Wirth, W. (2018). Measuring populist attitudes on three dimensions. International Journal of Public Opinion Research, 30(2), 316-326. Available here.
Please reflect on the following questions:
What is the research question of the study?
What are the research hypotheses?
Is EFA an appropriate method of analysis to answer the research question?
What are the main findings of the EFA?
And some more questions from the tutors:
What were the reasons that the initial 21 items were reduced to 15 items? And what is the advantage of excluding such items in the process?
Solution
From the text: “items were excluded when communalities or factor loadings were too low or when items loaded on more than one factor.” By excluding these items, the final model is more statistically reliable (i.e., a better fit), conceptually clearer as each factor only measures one idea, and therefore easier to interpret.
Consider all these values from the text: KMO = 0.89; eigenvalues = 5.68, 2.26, 1.59; Factor loadings ranged between .632 and .896. What do they tell us about the model?
Solution
KMO of 0.89 tells us that the data is suitable for factor analysis as it is >0.7. Kaiser’s criterion tells us that we have three factors to consider (their theoretical assumption). Factor loadings in this case support the current model, as they are significantly greater than 0.3.
If we consider the main body of the study, what might be lacking in terms of visualization/tests for EFA?
Solution
The analyses could include the following elements: a correlation analysis (to show if there is correlation of >0.9 between some variables); a Scree Plot as an alternative method of identifying number of factors; a graph of factor loadings; a naming procedure.
9.14 Time to practice on your own
You can download the PDF of the EFA exercises here:
9.14.1 Exercise 1: Big-5
To illustrate EFA, let us use the International Personality Item Pool data available in the psych package. It includes 25 personality self report items following the big 5 personality structure.
The first step is to test if the dataset is suitable for conducting factor analysis. To do so, run the Bartlett’s Test of Sphericity and the Kaiser Meyer Olkin (KMO) measure.
Reminder: Bartlett’s Test of Sphericity tests whether a matrix (of correlations) is significantly different from an identity matrix (probability that the correlation matrix has significant correlations among at least some of the variables in a dataset). KMO measure indicates the degree to which each variable in a set is predicted without error by the other variables (a KMO value close to 1 indicates that the sum of partial correlations is not large relative to the sum of correlations and so factor analysis should yield distinct and reliable factors).
The Kaiser-Meyer-Olkin (KMO) measure of sampling adequacy was 0.85, indicating that the correlations among items are sufficiently compact to justify factor analysis (values above 0.80 are considered meritorious). Individual MSA values for all items are above the acceptable threshold of 0.50, confirming their suitability.
The Bartlett’s test of sphericity was significant (p < .001), suggesting that the correlation matrix is not an identity matrix. This means that the variables share enough common variance to proceed with factor analysis.
Once you are confident that the dataset is appropriate for factor analysis, you can explore a factor structure made of 5 (theoretically motivated) latent variables. Start by defining the model.
What do you see? How can you interpret the output?
Solution: Interpretation
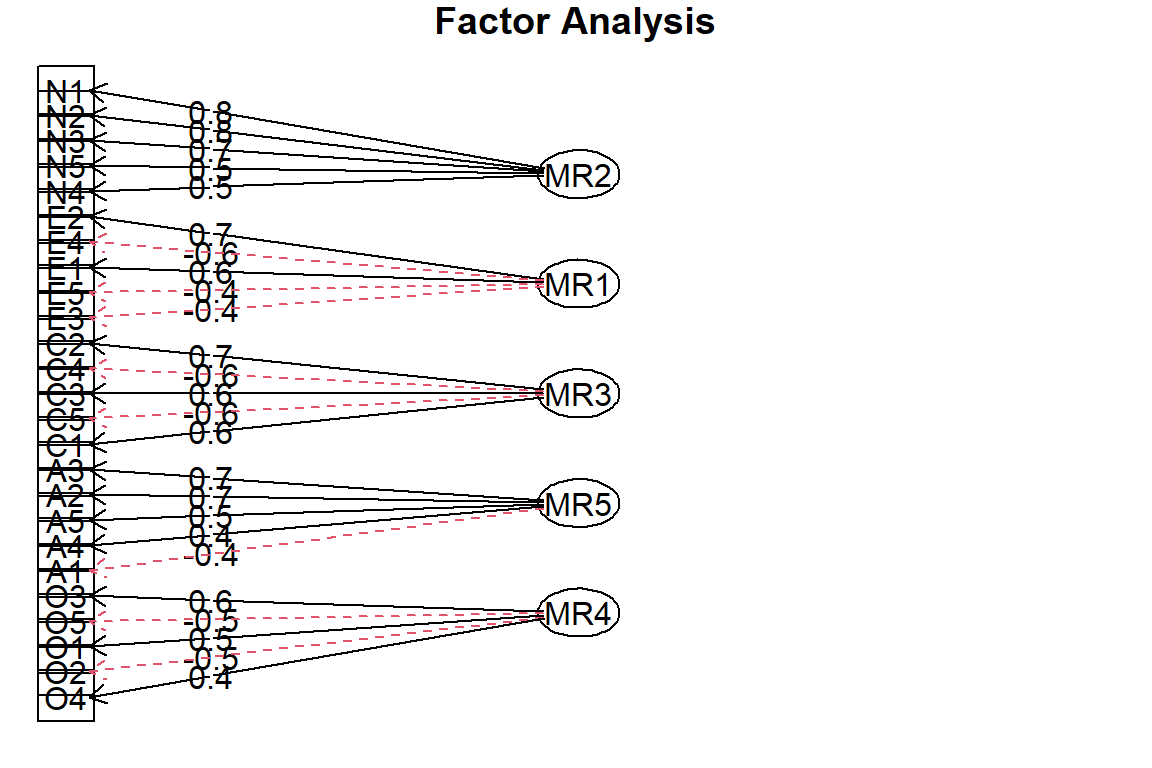
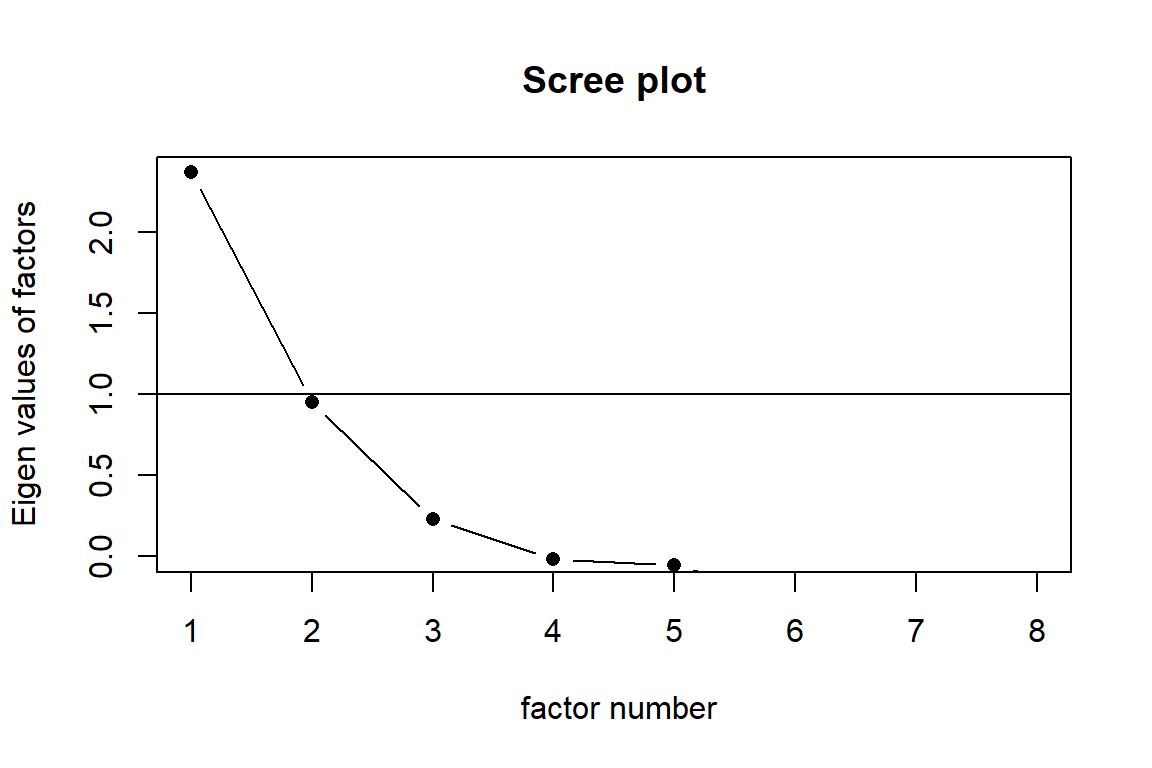
The eigenvalues from the correlation matrix show that five components have values greater than 1 (5.13, 2.75, 2.14, 1.85, and 1.55), following Kaiser’s criterion. This suggests that five factors should be retained. The 25 items spread on the 5 latent factors nicely - the famous big 5.
In the scree plot, there is a sharp drop after the first component, followed by a more gradual decline, but no distinct elbow or point of inflection that clearly separates the meaningful from the residual factors. The scree plot would suggest 3 factors.
This ambiguity suggests that while five factors might be statistically justified, the scree plot visually supports perhaps one dominant general factor and several smaller ones with diminishing explanatory power. Therefore, the number of factors should not be determined by the scree plot alone — it is better to use it in combination with parallel analysis or theoretical expectations (such as the Big Five model).
It is possible to visualize the results to ease the interpretation:
Show the code
loads <- efa$loadingspsych::fa.diagram(loads)
Tips: use the function predict() and give labels to the latent factors. Based on this model, you could predict back the scores for each individual for these new variables. This could be useful for further analysis (e.g. regression analysis).
Tips: use the function predict() and give labels to the latent factors.
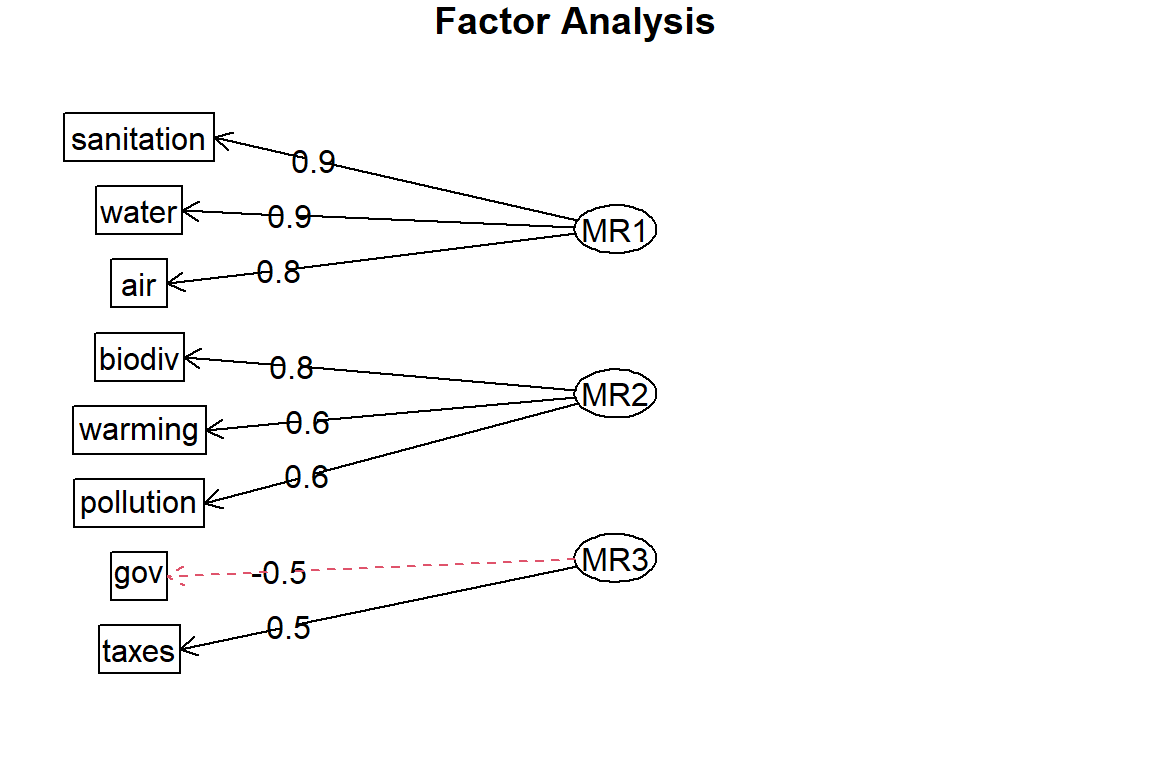
We will use survey data from the World Values Survey (WVS) website to investigate human belief and values, especially about environmental (EC) We will analyse Swiss data derived from the much larger WVS cross-country database (2007). The data can be downloaded here.
EC has been measured by a set of 8 items on a four-step Likert Scale. These items are thought to load on three different facets of EC: concerns about one’s own community (water quality, air quality and sanitation), concerns about the world at large (fears about global warming, loss of biodiversity and ocean pollution), willingness to pay/do more. We want to answer the following question: Is the three-factor model proposed by the structure of items (or can we assume a one-factor structure)?
Let’s first prepare the data and get the table of correlations:
The first step is to test if the dataset is suitable for conducting factor analysis. To do so, run the Bartlett’s Test of Sphericity and the Kaiser Meyer Olkin (KMO) measure.
Show the code
# option 1: check suitabilitypsych::KMO(sel)## Kaiser-Meyer-Olkin factor adequacy## Call: psych::KMO(r = sel)## Overall MSA = 0.72## MSA for each item = ## water air sanitation warming biodiv pollution taxes gov ## 0.71 0.84 0.70 0.69 0.66 0.74 0.62 0.50bartlett = psych::cortest.bartlett(sel)## R was not square, finding R from dataprint(paste0("Chi-2: ", round(bartlett[["chisq"]],2), "; p-value: ", bartlett[["p.value"]]))## [1] "Chi-2: 3331.64; p-value: 0"# option 2: check suitability# performance::check_factorstructure(sel)
Solution: Interpretation
The KMO was 0.72, indicating middling factorability (values between 0.70 and 0.80 are acceptable). Most individual MSA values are above 0.60, though the item gov is right at the lower limit (0.50), suggesting it may contribute less effectively to the shared variance structure.
The Bartlett’s test of sphericity was significant, confirming that the correlation matrix is not an identity matrix and that the variables share common variance.
Now, you can explore a factor structure made of 3 (theoretically motivated) latent variables. Start by defining the model.