The repeated measures ANOVA is used for analyzing data where same subjects are measured more than once on the same outcome variable under different time points or conditions. This test is also referred to as a within-subjects ANOVA (or ANOVA with repeated measures).
Repeated measures ANOVA is the equivalent of the one-way ANOVA, but for related, not independent groups, and is the extension of the dependent t-test.
In repeated measures ANOVA, the independent variable (also referred as the within-subject factor) has categories (called levels or groups). We can analyse data using a repeated measures ANOVA for two types of study design:
investigating changes in mean scores over three or more time points (e.g., pre-, midway and post-intervention)
investigating differences in mean scores under three or more different conditions
5.1.1 Within- and between-subject variables
For one withing-subject factor, we can consider the example where time is used to evaluate whether there is any difference in social media reliance across the several times of data.
We can also consider adding age cohort as a between-subject factor in order to test effect of age cohort on social media reliance, as well as the interaction effect between time and age cohort.
5.1.2 One-way and two-way repeated measurements analyis
An ANOVA with repeated measures is used to compare three or more group means where the participants are the same in each group. This usually occurs in situations when participants are measured multiple times to see changes to an intervention or when participants are subjected to more than one condition/trial and the response to each of these conditions wants to be compared.
One-way repeated measures ANOVA is an extension of the paired-samples t-test for comparing the means of three or more levels of a within-subjects variable.
Two-way repeated measures ANOVA is used to evaluate simultaneously the effect of two within-subject factors on a continuous outcome variable.
5.2 Assumptions
The repeated measures ANOVA makes the following assumptions:
No significant outliers
Normality of the dependent variable (at each time point)
We can use histograms and normality tests
Variance of the differences between groups should be equal (sphericity assumption)
We can use Mauchly’s test of Sphericity (if p>0.05, sphericity can be assumed).
Note that, if the above assumptions are not met there are a non-parametric alternative (Friedman test) to the one-way repeated measures ANOVA. However, there are no non-parametric alternatives to the two-way (and the three-way) repeated measures ANOVA. Thus, in the situation where the assumptions are not met, you could consider running the two-way repeated measures ANOVA on the transformed and non-transformed data to see if there are any meaningful differences.
5.3 Mauchly’s test of sphericity
Mauchly’s test of sphericity tests the null hypothesis (H0) that all variances can be considered homogeneous. A significant result leads to the rejection of H0 since at least two variances are unequal. Violations of sphericity lead to a biased F-test and to biased post-hoc test results!
There are two different ways of calculating sphericity violation:
Greenhouser & Geisser (1959): Rather conservative (the injuries are overestimated, especially in the case of minor injuries to the sphericity)
Huynh & Feldt (1976): Rather liberal (thus rather underestimated)
Stephen (2002) therefore recommends taking the arithmetic mean of the two estimates. The F value remains the same, but if the sphericity is violated, the interpretation of the F value must be adjusted. The degrees of freedom are corrected downwards, which means that the F value becomes significant less quickly.
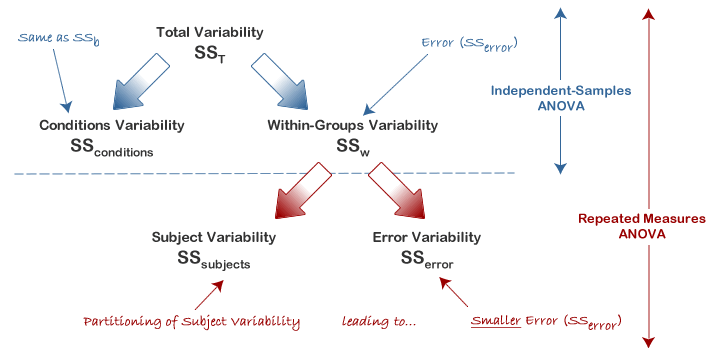
5.4 Logic of repeated measures ANOVA
The logic behind a repeated measures ANOVA is very similar to that of a between-subjects ANOVA. A between-subjects ANOVA partitions total variability into between-groups variability (\(SS_b\)) and within-groups variability (\(SS_w\)). Within-group variability (\(SS_w\)) is defined as the error variability (\(SS_{error}\)). Following division by the appropriate degrees of freedom, a mean sum of squares for between-groups (\(MS_b\)) and within-groups (\(MS_w\)) is determined and an F-statistic is calculated as the ratio of \(MS_b\) to \(MS_w\) (or \(MS_{error}\)).
\[ F=\frac{MS_b}{MS_w}=\frac{MS_b}{MS_{error}}\] A repeated measures ANOVA calculates an F-statistic in a similar way:
\[ F=\frac{MS_{conditions}}{MS_{error}}=\frac{MS_{time}}{MS_{error}}\] A repeated measures ANOVA can further partition the error term, thus reducing its size:
\[SS_{error}=SS_w-SS_{subjects}=SS_T-SS_{conditions}-SS_{subjects}\] This has the effect of increasing the value of the F-statistic due to the reduction of the denominator and leading to an increase in the power of the test to detect significant differences between means. With a repeated measures ANOVA, as we are using the same subjects in each group, we can remove the variability due to the individual differences between subjects, referred to as \(SS_{subjects}\), from the within-groups variability (SSw) by treating each subject as a block. That is, each subject becomes a level of a factor called subjects. The ability to subtract \(SS_{subjects}\) will leave us with a smaller \(SS_{error}\) term.
Now that we have removed the between-subjects variability, our new \(SS_{error}\) only reflects individual variability to each condition. You might recognize this as the interaction effect of subject by conditions (how subjects react to the different conditions).
Computation example for one-way repeated measures ANOVA
The calculation of \(SS_{time}\) is the same as for \(SS_b\) in an independent ANOVA, and can be expressed as:
\[SS_{time}=SS_b={\sum^{}_{}n_i(\overline{x}_i-\overline{x})^2}\] where \(k\) = number of conditions, \(n_i\) = number of subjects under each (ith) condition, \(\overline{x}_i\) = mean score for each (ith) condition, and \(\overline{x}\) = grand mean.
Within-groups variation (\(SS_w\)) is also calculated in the same way as in an independent ANOVA, expressed as follows:
\[SS_w={\sum^{}_{}(x_{i1}-\overline{x}_1)^2+\sum^{}_{}(x_{i2}-\overline{x}_2)^2+...+\sum^{}_{}(x_{ik}-\overline{x}_k)^2}\] where \(k\) = number of conditions, and \(x_{i1}\) = score of the ith subject in group 1.
We treat each subject as a level of an independent factor called subjects. We can then calculate \(SS_{subjects}\) as follows:
\[SS_{subjects}={k\sum^{}_{}(\overline{x}_i-\overline{x})^2}\] where \(k\) = number of conditions, \(\overline{x}_i\) = mean subject i, and \(\overline{x}\) = grand mean.
To determine the mean sum of squares for time (\(MS_{time}\)) we divide \(SS_{time}\) by its associated degrees of freedom \((k-1)\):
\[MS_{time}=\frac{SS_{time}}{(k-1)}\] We do the same for the mean sum of squares for error (\(MS_{error}\)), this time dividing by \((n-1)(k-1)\) degrees of freedom:
\[MS_{time}=\frac{SS_{error}}{(n-1)(k-1)}\]
5.5 F-statistic
The sums of squares depend on the number of measurement times and cases, so the variance (standardized SS) is used to calculate the F-statistic.
We can calculate the F-statistic as:
\[F=\frac{MS_{time}}{MS_{error}}\] We can then ascertain the critical F-statistic for our F-distribution with our degrees of freedom for condition and error, and determine whether our F-statistic indicates a statistically significant result.
The figure below shows that the calculation of the F-statistic for repeated measures ANOVA offers very different results compared to the results that would be obtained using the calculation for independent ANOVA. You can click on the figure to download the excel file.
F-statistic calculation
5.6 Two-way repeated measures ANOVA
A two-way repeated measures ANOVA compares the mean differences between groups that have been split on two within-subjects factors (also known as independent variables). A two-way repeated measures ANOVA is often used in studies where you have measured a dependent variable over two or more time points, or when subjects have undergone two or more conditions (e.g., “time” and “conditions”).
Remember that the two-way (repeated measures) ANOVA is an omnibus test statistic and cannot tell you which specific groups within each factor were significantly different from each other. It only tells you that at least two of the groups were different. To determine which groups differ from each other, you can use post hoc tests.
5.7 Effect size
The partial eta-squared is specific to the factor \(i\), but if there are several factors, you cannot add the individual partial eta-squares to form a total value because the denominator does not contain the total sum of squares (total variance)!
Partial eta-squared is where the the \(SS_{subjects}\) has been removed from the denominator:
Eta-square overestimates the effect (i.e. the explained variance shares are assumed to be too large), because in samples there are very likely to be group differences even if there are no differences in the total population (especially with small n)!
Therefrore, a recommendation of many authors is not to use the measured variances (SS) as the basis for the calculation of effect sizes, but their estimates in the total population (then no more bias). This parameter is called omega-square.
5.8 Pairwise comparisons
There are several methods to conduct pairwise comparisons:
Contrasts: particularly useful for repeated measurement designs: each measurement time point is tested against the previous one: t2 vs. t1, t3 vs. t2, etc.
Post-hoc tests (Bonferroni correction is recommended for violations of sphericity)
Simple Effects also possible
5.9 Recap on the models’ assumptions
Below is a recap of the assumptions of the different models that we have seen so far (linear regression, ANOVA, repeated measures ANOVA). The assumptions are defined, methods and tests are highlighted, as well as solutions proposed.
Models’ assumptions
5.10 In a nutshell
In the ANOVA with repeated measures, a distinction is made between the between-participant and the within-participant variance.
The within-participant variance can be further subdivided into model explained variance and unexplained (error) variance. The F-value is calculated from their ratio.
Partial eta-squared is often reported as a measure of effect size. It reflects the proportion of variance explained by a specific factor after removing the variance explained by other factors from the denominator.
A prerequisite for the ANOVA with repeated measurements is sphericity (i.e. homogeneous variances between the measurement times). The Mauchly’s test checks this requirement, it should not be significant. If there is no sphericity, the degrees of freedom for the critical F-value must be corrected (refer to Greenhouser & Geisser and Huynh & Feldt).
Feature
Regular (Between-Subjects) ANOVA
Repeated Measures (Within-Subjects) ANOVA
Primary variance source
Variance between groups
Variance within subjects across conditions/time
Error term
Based on differences within groups
Based on differences within subjects
Key assumption
Homogeneity of variance: group variances are equal
Sphericity: variances of the differences between all pairs of conditions are equal
Question addressed
“Are group spreads similar?” (differences between people)
“Are within-person change spreads similar across all pairs of time points or conditions?”
5.11 How it works in R?
Important note: For repeated measures ANOVA in R, it requires the long format of data. For the long format, we would need to stack the data from each individual into a vector (data at each time in a single column). If the database is in short format (data at each time in different columns), the function melt() from the R package reshape2 can be used. See the lecture slides on repeated measures ANOVA:
You can also download the PDF of the slides here:
5.12 Quiz
True
False
Statement
When Mauchly’s test for equality of variances fails to show significance, you have evidence that the data are suitable for the application of the one-way repeated measures ANOVA.
When conducting a one-way repeated measures ANOVA test a significance level of 0.506 indicates that the means are equal.
Conducting pairwise comparisons helps to assess which groups a statistically different.
In a two-way repeated measures ANOVA the distribution of the dependent variable in each combination of the related groups should be approximately normally distributed.
My results will appear here
5.13 Example from the literature
The following article relies on repeated measurements ANOVA as a method of analysis:
Hameleers, M., Brosius, A., & de Vreese, C. H. (2021). Where’s the fake news at? European news consumers’ perceptions of misinformation across information sources and topics. Harvard Kennedy School Misinformation Review. Available here.
Please reflect on the following questions:
What is the research question of the study?
What are the research hypotheses?
Is repeated measurements ANOVA an appropriate method of analysis to answer the research question?
Solution
The study’s questions explicitly ask: RQ1: Which sources do people associate most with misinformation? RQ2: Which topics do people associate most with misinformation? Each respondent rated multiple information sources and multiple topics on the same scale (1–7) for how much misinformation they perceive in each. Both questions involve comparing mean perceptions across several conditions within the same sample. Repeated measures ANOVA tests whether the mean differences across conditions (sources or topics) are statistically significant within individuals. Because the measures are within-subjects (repeated measures), the appropriate test to compare mean differences across those categories is repeated measures ANOVA. Repeated measures ANOVA accounts for the intra-individual correlation among measures (unlike a one-way ANOVA, which assumes independence). This reduces error variance and increases power.
Some assumptions should be checked:
Sphericity: equality of variances of differences between all pairs of conditions. If violated, corrections like Greenhouse-Geisser should be applied.
Normality of residuals: though large sample sizes make ANOVA robust to mild violations.
What are the main findings of the repeated measurements ANOVA analysis?
And some more questions from the tutors:
In terms of RQ1 (sources of misinformation), the general repeated-measurements ANOVA is significant (F = 93.0, p < .01). However, the question is: what specific sources do differ from one another significantly? Which test do we use to identify it?
Solution
From the text: “Based on Bonferroni-adjusted pairwise comparisons, the only pairs whose means are not significantly different are the government and citizens as well as the news media and foreign countries.”
Regarding the topics people associate with misinformation, what are the topics with the biggest difference in means of misinformation association?
Solution
Based on the Figure 2, those are education and immigration, where education is the least associated with misinformation, and immigration - the most
Consider the study design: how can the way and context in which a survey is conducted affect the results? How can this be mitigated?
Solution
If the survey solely focuses on misinformation, participants might be primed to perceive misinformation as a particularly salient or serious issue. This priming could lead them to inflate their reported perceptions of misinformation, as they might infer from the survey’s emphasis that it is an important societal problem (this might explain that all means exceed the mid-point of the scale). In this study, however, such bias may be partly mitigated by the fact that “the data collection effort of this study was part of a larger seven-wave project on attitudes toward the European Union”. However, “data used for this project were mostly collected in the final wave (July, 2019), with the exception of most sociodemographic variables and the variables measuring issue importance and anti-immigration attitudes”. Accordingly, the extent of this mitigating effect likely depends on the content and framing of the other questions included in the seventh wave.
5.14 Time to practice on your own
You can download the PDF of the exercises here:
5.14.1 Exercise 1: strengthening environmental protection over time
Use the data from the Selects 2019 Panel Survey and assess whether respondents’ stance towards strengthening environmental protection has increased over the first three waves (before, during and after the campaign).
Start by downloading the data and by selecting the variables.
Next, reshape the data so that there are in a long format.
Show the code
long <-reshape(as.data.frame(sel),direction="long",varying =c("W1_f15340d","W2_f15340d","W3_f15340d"),v.names ="pro_env",times =c("wave1","wave2","wave3"))
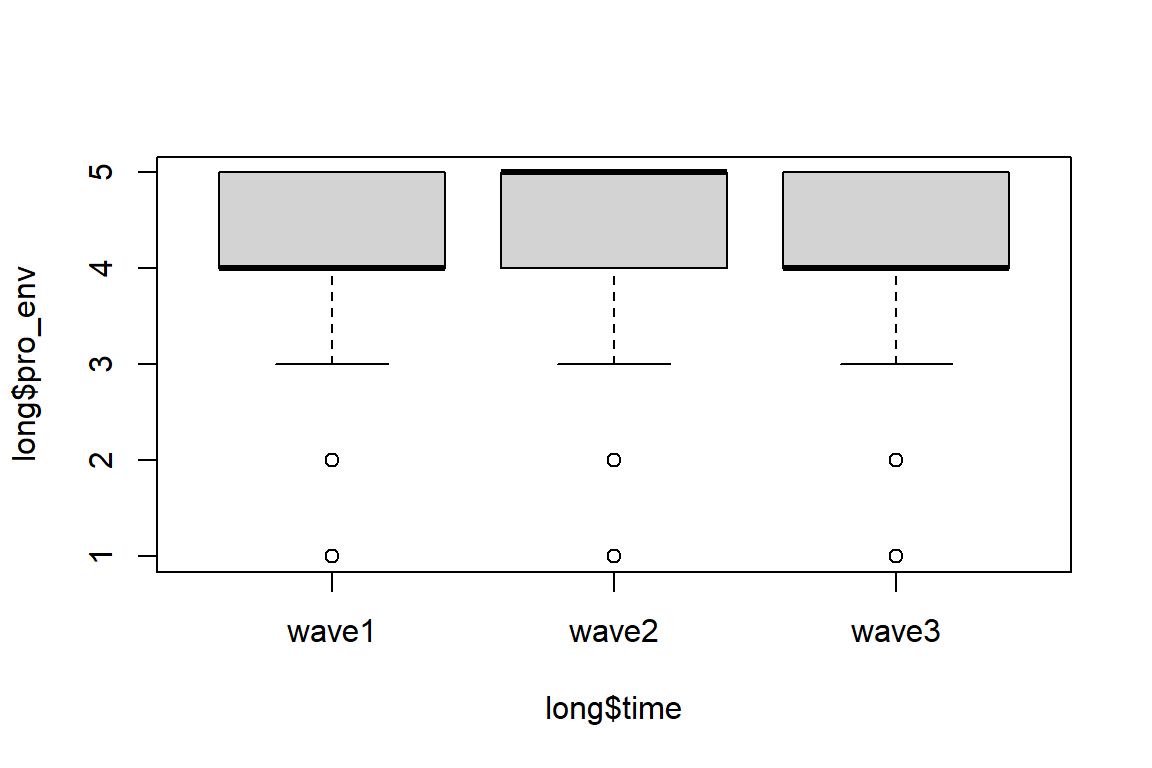
Then, we can check the normality of the dependent variable using the Shapiro-Wilk normality test:
If the data is normally distributed, the p-value should be greater than 0.05., which is not the case here. Note that we need to test if the data was normally distributed at each time point. You can also visualize the distribution over time using boxplots.
Nota bene: If your sample size is greater than 50, the normal QQ plot is preferred because at larger sample sizes the Shapiro-Wilk test becomes very sensitive even to a minor deviation from normality.
The assumption of sphericity will be automatically checked during the computation of the ANOVA test using the R function anova_test(). By using the function get_anova_table() to extract the ANOVA table, the Greenhouse-Geisser sphericity correction is automatically applied to factors violating the sphericity assumption. Now, we can check whether there are group differences:
Show the code
# group differencesres.aov <- rstatix::anova_test(data = long, dv = pro_env, wid = id, within = time)res.aov## ANOVA Table (type III tests)## ## $ANOVA## Effect DFn DFd F p p<.05 ges## 1 time 2 3682 37.718 6.09e-17 * 0.004## ## $`Mauchly's Test for Sphericity`## Effect W p p<.05## 1 time 0.993 0.001 *## ## $`Sphericity Corrections`## Effect GGe DF[GG] p[GG] p[GG]<.05 HFe DF[HF] p[HF] p[HF]<.05## 1 time 0.993 1.99, 3655.01 7.76e-17 * 0.994 1.99, 3658.94 7.49e-17 *
The sphericity test is violated (W=0.993 and p<0.05). Therefore, we need to look at the Greenhouser-Geisser (GG) Huynh-Feldt (HF) corrections. The p-values (p[GG] and p[HF]) are significant, thus indicating that the observed F values are significant and accepting the hypothesis that we have different means.
Interpretation
The pro-environment score was statistically significantly different at the different time points: F = 37.71, p < 0.05. Furthermore, the value for “ges” (generalized effect size) gives us the amount of variability due to the within-subjects factor.
Finally, we can assess which group (or time) differences are statistically significant:
Show the code
# Post-hoc test to assess differencespwc <- long |> rstatix::pairwise_t_test( pro_env ~ time, paired =TRUE,p.adjust.method ="bonferroni" )pwc[,c(2,3,6,8,10)]## # A tibble: 3 × 5## group1 group2 statistic p p.adj.signif## <chr> <chr> <dbl> <dbl> <chr> ## 1 wave1 wave2 -3.15 2 e- 3 ** ## 2 wave1 wave3 5.26 1.58e- 7 **** ## 3 wave2 wave3 8.80 3.19e-18 ****
Interpretation
The pairwise post-hoc comparisons with Bonferroni correction show that all waves differ significantly from each other:
Wave 1 vs. Wave 2: the difference is statistically significant (t = -3.15, p < 0.01), indicating a change in pro-environment attitudes between these two time points.
Wave 1 vs. Wave 3: the difference is highly significant (t = 5.26, p < 0.001), showing that pro-environment attitudes increased strongly from before to after the campaign.
Wave 2 vs. Wave 3: the difference is also highly significant (t = 8.80, p < 0.001), suggesting a further increase in pro-environment attitudes from during to after the campaign.
Overall, these results confirm that respondents’ stance towards strengthening environmental protection increased consistently and significantly across the three survey waves.
5.14.2 Exercise 2: two-way repeated measure ANOVA
Let’s create a dataset containing a score measured at three points in time. In a second step, we will investigate if (frequently) working in group can induce a significant increase of the score over time.
Show the code
data <-data.frame(matrix(nrow =200, ncol =0)) set.seed(123)data$score1 <-runif(nrow(data), min=2, max=4.5)data$score2 <-runif(nrow(data), min=1.5, max=6)data$score3 <-runif(nrow(data), min=3, max=5.5)# assign iddata$id =rep(seq(1:100),2)# assign group work variabledata$groupwork =c(rep(c("always"),100), rep(c("no"),100))# copy of the data copy = data# re-arrange the datadata <- data |> tidyr::gather(key ="time", value ="score", score1, score2, score3) |> rstatix::convert_as_factor(id, time)
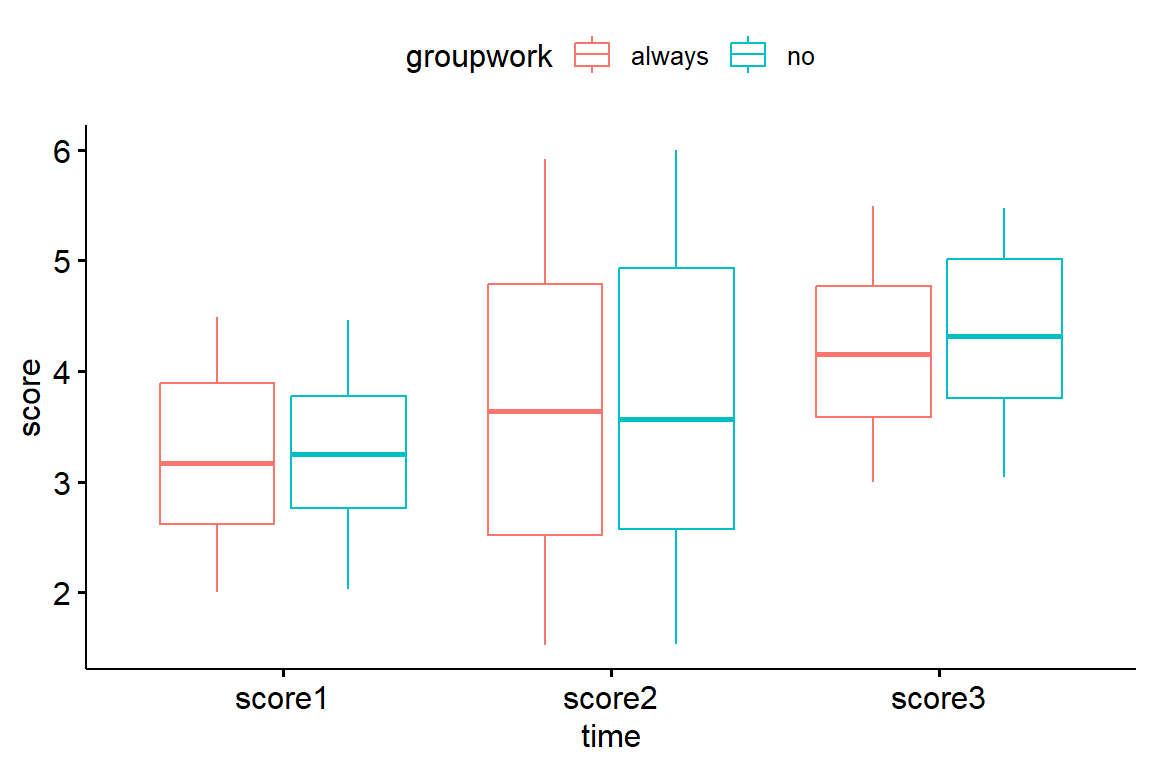
Now, we will test whether there is significant interaction between working in group and time on the score. We can use boxplots of the score colored by working in group:
Show the code
ggpubr::ggboxplot( data, x ="time", y ="score",color ="groupwork" )
We can check whether there are outliers:
Show the code
data |> dplyr::group_by(groupwork, time) |> rstatix::identify_outliers(score)## [1] groupwork time id score is.outlier is.extreme## <0 rows> (or 0-length row.names)
We next compute Shapiro-Wilk test to test for the normality assumption for each combinations of factor levels:
We can assess whether there is a statistically significant two-way interactions between group work and time:
Show the code
# We also need to convert id and time into factor variables # data$groupwork <- as.factor(data$groupwork)data$time <-as.factor(data$time)data$id <-as.factor(data$id)res.aov <- rstatix::anova_test(data = data, dv = score, wid = id,within =c(groupwork, time) )# rstatix::get_anova_table(res.aov)res.aov## ANOVA Table (type III tests)## ## $ANOVA## Effect DFn DFd F p p<.05 ges## 1 groupwork 1 99 0.454 5.02e-01 0.000696## 2 time 2 198 46.979 2.01e-17 * 0.153000## 3 groupwork:time 2 198 0.050 9.51e-01 0.000163## ## $`Mauchly's Test for Sphericity`## Effect W p p<.05## 1 time 0.791 0.0000101 *## 2 groupwork:time 0.809 0.0000317 *## ## $`Sphericity Corrections`## Effect GGe DF[GG] p[GG] p[GG]<.05 HFe DF[HF] p[HF]## 1 time 0.827 1.65, 163.74 7.74e-15 * 0.839 1.68, 166.17 5.07e-15## 2 groupwork:time 0.840 1.68, 166.31 9.28e-01 0.853 1.71, 168.85 9.30e-01## p[HF]<.05## 1 *## 2
Interpretation
There is a statistically no significant two-way interactions between group work and time, F = 0.05, p > 0.05. Furthermore, the shericity test is violated, thus suggesting to look at the GG and HF corrections.
Procedure for post-hoc test:
A significant two-way interaction indicates that the impact that one factor (e.g., group work) has on the outcome variable (e.g., score) depends on the level of the other factor (e.g., time), and vice versa. So, you can decompose a significant two-way interaction into:
simple main effect (one-way model of the first variable at each level of the second variable: e.g., group work at each time point);
simple pairwise comparisons if the simple main effect is significant (pairwise comparisons to determine which groups are different: e.g., pairwise comparisons between categories of group work).
For a non-significant two-way interaction, you need to determine whether you have any statistically significant main effects from the ANOVA output (e.g., comparisons for group work and time variable).
Show the code
# Comparisons for group workres1 = data |> rstatix::pairwise_t_test( score ~ groupwork, paired =TRUE,p.adjust.method ="bonferroni")res1[,c(2,3,6,8,10)]## # A tibble: 1 × 5## group1 group2 statistic p p.adj.signif## <chr> <chr> <dbl> <dbl> <chr> ## 1 always no -0.661 0.509 ns# Comparisons for the time variableres2 = data |> rstatix::pairwise_t_test( score ~ time, paired =TRUE,p.adjust.method ="bonferroni")res2[,c(2,3,6,8,10)]## # A tibble: 3 × 5## group1 group2 statistic p p.adj.signif## <chr> <chr> <dbl> <dbl> <chr> ## 1 score1 score2 -4.05 7.31e- 5 *** ## 2 score1 score3 -13.5 5.28e-30 **** ## 3 score2 score3 -5.04 1.02e- 6 ****
Interpretation - Group Work
The pairwise comparison between students who reported always working in groups and those who reported never working in groups shows no statistically significant difference in their mean scores (t = -0.66, p = 0.509). This suggests that group work, in this dataset, does not have a measurable effect on the outcome variable.
Interpretation - Time
The pairwise comparisons across time points reveal clear and statistically significant differences:
Score 1 vs. Score 2: significant increase (t = -4.05, p < 0.001).
Score 1 vs. Score 3: highly significant increase (t = -13.5, p < 0.001).
Score 2 vs. Score 3: also highly significant (t = -5.04, p < 0.001).
These results indicate that mean scores rose consistently and substantially across all three time points, with the largest jump occurring between the first and the third measurement.