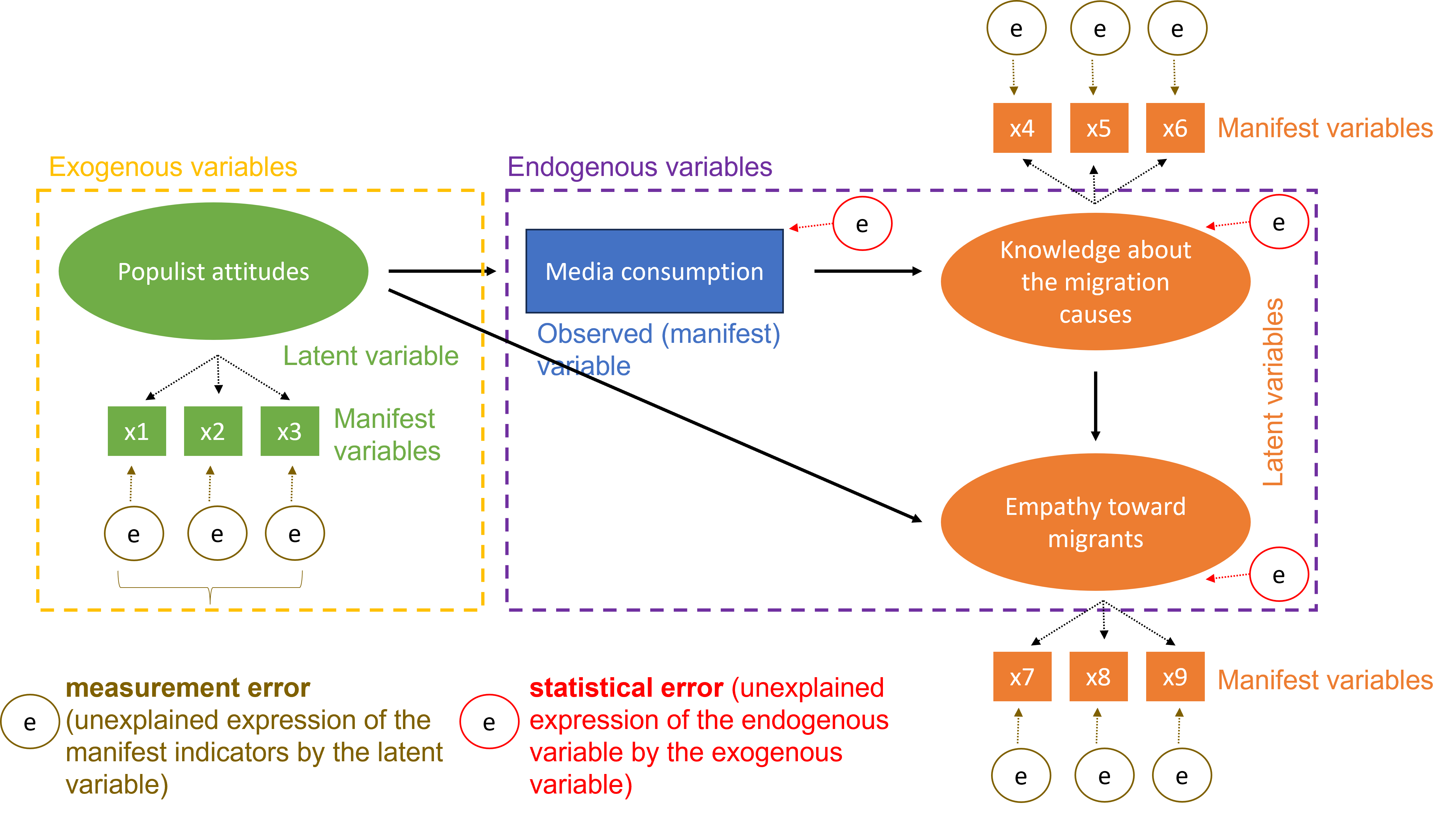
CFA is a structure-testing procedure which enable us to answer questions such as: Do my data confirm my previously made hypothetical assumptions about their (factorial) structure?
SEM is a structure testing technique. It enables us to answer questions such as: Do my data confirm my previously made hypothetical assumptions about the “causal” structure between variables? Causal structures can be diverse and SEM can flexibly map this diversity. Structural equation models are about testing (sometimes very complex) “causal” structures between (potentially many) variables.
Simply speaking, a structural equation model (SEM) is a combination of confirmatory factor analysis and path analysis.
Structural equation modeling includes two sets of models:
the measurement model
the structural model
The measurement model can be expressed as a factor model. The figure below displays a model to measure political trust using three variables - trust in parliament, trust in government and trust in court. It also measures satisfaction with democracy (SWD) using three variables - media use, political interest and feeling of self-efficacy. If one believes that satisfaction with democracy influences political trust, then one can fit a path model. Therefore, a structural model is actually a path model.
12.2 Logic of SEM and similarity with CFA
SEM are hypothesis-testing methods. In this context, previously theoretically deduced considerations on relationships between variables are tested using empirical data. It is thus determined in advance which variables may/should be related and which should not (similar to CFA).
As with the CFA, it is a comparison of covariance matrices that are checked as a whole:
empirical variance-covariance matrix (= actual correlations between all examined variables in the data)
model-theoretical variance-covariance matrix (= expected relationships between all variables examined)
The aim is that the model-theoretical matrix is able to reproduce the empirical matrix. SEM allow the testing of entire hypotheses systems in one model.
12.3 Comparison to “normal” regression
SEM follow the intuitive logic of causal models. We can thus assess simultaneous and overall testing of several “causal” relationships in one model instead of testing individual hypotheses in different analyzes.
For instance, linear regression models unrealistically assumes that constructs are perfectly measured, thus confusing measurement error with statistical error (e.g. unexplained variance).
SEM with latent variables allow the measurement error to be extracted from the statistical error. Therefore, SEM come with potentially more exact estimation of the significance and strength of the connections between latent variables.
12.4 Construct validity, model fit, and better explanation of relationships
SEM seeks to find a balance between maximizing the variance between constructs while ensuring the model remains parsimonious and generalizable.
Maximizing the sum of squares between constructs can be useful in several respects:
Reliability and Validity Assessment: higher variance suggests that the latent variable accounts for a larger proportion of the variation in the observed indicators, which contributes to the construct’s reliability and validity.
Model Fit and Explanation of Relationships: a model that explains a higher proportion of the variance in the observed variables tends to fit the data better.
Precision in Estimation (robustness of conclusions): higher variance between constructs often results in more precise estimates of the relationships among constructs.
12.5 Quick recap of the concepts
A SEM thus specify causal relationships between exogenous and endogenous variables. Below is a quick recap of the core concepts:
Observed variable: Exists in data
Indicator: Observed (exogenous or endogenous)
Latent variable: Constructed in model
Factor: Latent (exogenous or endogenous)
Exogenous: Independent that explains endogenous (observed or latent) (predictor)
Endogenous: Dependent that has a causal path leading to it (observed or latent) (response)
Measurement model: Links observed and latent variables
Loading: Path between indicator and factor
Regression model: Path between exogenous and endogenous variables
12.6 Latent variables
In the structural model, the (“causal”) relationships between different variables are formulated (directed relationships!). These variables can be both latent (= hypothetical, not directly observable) and manifest (= directly observable) constructs.
Latent variables are specified in the measurement model (like CFA) and are estimated in such a way that they best represent their respective manifest indicators (items). Manifest constructs (not indicators!) of the structural model are not part of the latent variable measurement model.
12.7 Statistical error versus measurement error
SEM with latent variables allow the distinction between statistical error in estimating the “causal” influences of the exogenous on the endogenous variables (unexplained expression of the endogenous variable by the exogenous variable) and the measurement error of the variable (unexplained expression of the manifest indicators by the latent variable).
Analyzes with only manifest variables (e.g., ANOVA, multiple regression, mediation, path models) mix up the statistical error and the measurement error and implicitly assume perfectly reliable measurements. Since this is unrealistic and there should be measurement errors even with manifest variables (e.g., not perfect reliability), the statistical error (unexplained variance) may be larger than it actually is if the measurement error were included.
12.8 Path models
A path model is a special case of a SEM in which the structural model is present but the measurement model is omitted (exclusively manifest constructs in the structural model).
Path models can also be calculated as SEM in the covariance analysis approach (including model quality measures, etc.), but for better differentiation they are not called SEM but path models.
More vocabulary
SEM without latent variables (i.e. with structural model but without measurement model), synonymous terms:
Path analysis
Path model
IMPORTANT: Do not confuse the terms with the “path diagram” (path diagram = only the graphical representation of relationship structures between variables; path diagrams can be used for SEM with and without latent variables created)
SEM with at least one latent variable (i.e. with a structural model and at least one measurement model) has synonymous terms:
Structural equation model
Causal analysis (caution: despite SEM, causality still depends on the data collection method, more later)
Covariance structure analysis
12.9 Prerequisites
There are several mathematical prerequisites:
Rule of thumb: sample size K at least 200 (also K - q > 50, where K is the sample size and q is the number of free parameters to be estimated)
If only latent variables in the structural model:
Prerequisites as for CFA
Reflective measurement model
Interval-scaled and reasonably normally distributed manifest indicator variables
If partially latent and partially manifest constructs in the structural model:
SEM can handle a mixture of manifest and latent constructs in the structural model very well
Structural equation system must be identifiable, i.e. the equation system must be mathematically solvable (similar to CFA)
There are also theoretical prerequisites:
Theoretically secured hypotheses about the connection between constructs in the SEM
Especially with cross-sectional data: theoretically reasonable deduced “causal direction” (which constructs are exogenous, which endogenous?)
Adhere to the confirmatory character of the analysis or, if this is not done, then deal with it transparently
Strictly confirmatory testing: If we proceeded strictly confirmatory, we could only specify one model and accept or reject it with a test (hypothesis testing).
Alternative models testing: Testing different plausible theories against each other
Generating adaptation of the model until the data “fit”
12.10 Identification of the structure
The identification of the model structure consists of two “tasks”:
Establishing a metric for the latent constructs.
Checking whether there is enough information to estimate the model.
Both steps influence the number of degrees of freedom of the model (model degrees of freedom). This aspect also relates to the complexity of the model. The more complex a model is, the more parameters have to be estimated, and the greater the model’s degrees of freedom must be in order to make the estimation possible.
Important: This is not about the sample size, which can also be used to determine “degrees of freedom”. Observations do not mean individual cases here, but the number of manifest variables (number whether observed variables).
12.10.1 Establishing metric
The latent variables and error variables to be estimated initially have no metric. In order to be able to interpret the variable later, a scale must be assigned.
One possibility is to choose a reference variable and fix the factor loading to 1. With regard to the latent variable, the “best” indicator variable should be selected (i.e. the variable that is assumed to best index the latent variable). It means that the latent variable is identical to the selected indicator variable except for the measurement error.
In addition, all relationships between the measurement error terms to be estimated and the measured indicator variables are fixed at 1. It means that the measurement errors to be estimated correspond to the observed values except for the influence of the latent variables (everything that is not affected by the latent variable in the indicator variable is explained is a measurement error).
Nota bene: For each fixed parameter, we gain one model degree of freedom (no longer needs to be estimated).
12.10.2 Checking model information
If n manifest variables are collected as part of a project, empirical variances and covariances can be calculated from these variables:
\[ p = \frac{n(n+1)}{2} \] , where \(p\) corresponds to the number of non-redundant values in the variance-covariance matrix. It thus corresponds to the available “information” that we use as the basis for calculating all free parameters of our model.
The difference between the available empirical information (\(p\)) and the number of (free) parameters to be estimated (\(q\)) gives the degrees of freedom of the model (\(df_M\)).
\[ df_M = p - q \] If the empirically available information is the same as the number of parameters to be estimated, the number of model degrees of freedom corresponds to zero. The number of model parameters to be estimated must not be less than the number of empirical information given, otherwise a model is not identified (i.e., not solvable). The degrees of freedom of the model must be > or equal to zero for a specified model to be considered identified.
Degree of freedom: calculation for SEM
Recall that the formula for calculation degrees of freedom is as follows:
\[ df = \frac{m(m+1)}{2} - 2m - \frac{X(X-1)}{2} \] where \(m\) represent the number of indicators and \(X\) the number of independent latent constructs.
For SEM, this formula includes two additional parameters:
\[ df = \frac{m(m+1)}{2} - 2m - \frac{X(X-1)}{2} - g - b\] where \(m\) represent the number of indicators, \(X\) the number of independent latent constructs, \(g\) the structural relationships from independent to dependent constructs, and \(b\) structural relationships from dependent to dependent constructs.
In the above example, we have 9 indicators (\(m\)) and 1 independent latent construct (\(X\)). Furthermore, we have 2 gamma relationships and 1 beta relationship. Applying the formula, we obtain:
Model Specification - defines hypothetical relationships
Model Identification:
Over identified - more known than free parameters
Just-identified - the number of unknown equals the number of free parameters
Under-identified - the number of unknown is greater than the number of parameters (model coefficients cannot be estimated)
Parameter Estimation - comparing actual and estimated covariance (i.e. maximum likelihood estimate)
Model Evaluation- goodness of fit (i.e. Chi-square, Akaike Information Criterion, Comparative Fit Index)
Model Modification - post hoc model modification
12.11.1 Chi-square test
The Chi-Square test poses that:
H0: empirical covariance matrix is equal to the model-theoretical covariance matrix
H1: empirical covariance matrix is not equal to the model-theoretical covariance matrix
The smaller the difference between the two matrices, the smaller the chi-square value. So, the smaller the chi-square is, the better it is. The test should not turn out to be significant, since equality between the empirical and model-theoretical variance-covariance matrix is desirable.
12.11.2 RMSEA (Root Mean Squared Error of Approximation)
RMSEA uses inferential statistics to check whether a model can approximate reality well (approximation test). It is therefore not about the absolute correctness of the model, as with the Chi-Square test, but about evaluating the best possible approximation.
Recommendations:
RMSEA < .05 good fit (also test of the characteristic value: p close > .1, means that RMSEA is clearly not significantly larger than RMSEA < .05)
RMSEA < .08 acceptable fit (also test of the parameter: .05 < p close < .1 means that RMSEA does not tend to be significantly larger than RMSEA < .05)
12.11.3 SRMR (Standardized Root Mean Squared Residual)
Usually there is a discrepancy between the empirical and model-theoretical covariance matrix. Therefore, descriptive measures of discrepancy are often used. These give an answer to the question of whether an existing discrepancy can be neglected and also includes the model complexity. If the empirical and model-theoretical covariance matrix are completely identical, this measure assumes a value of zero.
Recommendations:
SRMR < .05 good fit
SRMR < .10 acceptable fit
12.12 Individual components
Have the individual components of the SEM (entire measurement model AND structural model) also been identified? For structural models, this depends heavily on the structure:
Recursive models (= models without repercussions between endogenous variables, i.e. directed models) are always identified
Non-recursive models (= models with repercussions between endogenous variables, i.e. undirected models) are difficult to determine by hand, you should leave that to the statistics program
12.13 Critics to SEM
SEM seems to test causal relationships between exogenous and endogenous variables and is even called causal analysis. But, ultimately, only relationships between variables become statistical examined and the researcher decides (often) what are exogenous and what are endogenous variables.Directions of impact could be directed in the opposite direction as long as the method of data collection is cross-sectional. Causal evidence using SEM is only possible with panel data or in an experiment (and then not mandatory for all paths of the structural model).
In practice, SEM are too often not tested for confirmation, but adjusted until the model fit is “good”, without this being reported transparently. The more paths between variables are freely estimated in the structural model, the less SEM test theoretical ideas. More parsimonious models in which more parameters are fixed a priori (e.g., direct effects in SEM mediation models set to 0) test assumptions, but if everything is allowed to be related to everything (i.e., freely estimated), then there are no assumptions more that are tested, just a SEM that fits the data.
Interesting resource: Shah, R., & Goldstein, S. M. (2006). Use of structural equation modeling in operations management research: Looking back and forward. Journal of Operations management, 24(2), 148-169. https://doi.org/10.1016/j.jom.2005.05.001
12.14 In a nutshell
SEM is a confirmatory, hypothesis-testing framework that combines confirmatory factor analysis (measurement model) and path analysis (structural model) to test complex causal structures among observed and latent variables.
It allows simultaneous testing of multiple causal paths, separates measurement error from statistical error, and provides more accurate estimates of relationships between constructs than standard regression.
SEM compares two matrices: the empirical covariance matrix (actual relationships in the data) and the model-implied covariance matrix (relationships expected under the hypothesized model). A good SEM model reproduces the empirical matrix well.
Key Concepts:
Observed/manifest variables = measured directly
Latent variables/factors = theoretical constructs measured via indicators
Exogenous variables = predictors
Endogenous variables = outcomes
Measurement model = how indicators load on latent variables
Structural model = how latent/manifest variables causally influence one another
Path Models: A simplified SEM without latent variables—only observed constructs and structural paths.
Identification: A model must have enough information to be solvable. Fixing loadings (e.g., setting one loading to 1) establishes the latent variable’s scale.
Fit Evaluation:
Chi-square: nonsignificant = good (model fits data)
RMSEA: < .05 good; < .08 acceptable
SRMR: < .05 good; < .10 acceptable
SEM models must balance fit, parsimony, and theoretical justification.
Strong theoretical rationale for directional paths
Transparent reporting, especially if model modifications are made
Possible critiques:
SEM tests covariance patterns, not true causality, unless supported by design (panel/experimental data).
Over-fitting and post-hoc model tinkering undermine the confirmatory nature of SEM.
Too many freely estimated paths dilute theoretical rigor.
12.15 How it works in R?
See the lecture slides on SEM:
You can also download the PDF of the slides here:
12.16 Quiz
True
False
Statement
If SEM is proven to have a good fit, this means that causality can be confirmed.
SEM can handle both latent and manifest variables correctly in the same model.
OLS is better than SEM, because it tackles the effects of measurement error more effectively.
SEM is especially suitable to be used with small samples (n<100).
My results will appear here
12.17 Example from the literature
The following article relies on SEM as a method of analysis:
Gil de Zúñiga, H., González-González, P., & Goyanes, M. (2021). Pathways to political persuasion: Linking online, social media, and fake news with political attitude change through political discussion. American Behavioral Scientist, 00027642221118272. Available here.
Please reflect on the following questions:
What is the research question of the study?
What are the research hypotheses?
Is SEM an appropriate method of analysis to answer the research question?
What are the main findings of the SEM?
And some more questions from the tutors:
The goodness of fit of the SEM model is identified as follows: Goodness of fit: χ²=4.09; df=3; p=.25; RMSEA=0.027, CFI=0.995, TLI=0.986, SRMR=0.022. Is it a good, an acceptable, or a bad fit?
Solution
It is a good fit, as the Chi Square is not significant, RMSEA and SRMR are much lower than the 0.05 threshold, and CFI and TLI are high.
There are three types of confirmatory analysis strategies in SEM: strictly confirmatory testing alternative models testing, and model adaptation. Describe the differences and what type of confirmatory strategy the analysis in the paper follows.
Solution
Strictly confirmatory testing: we only specify one model and accept or reject it with a test (hypothesis testing).
Alternative models testing: testing different plausible theories against each other (see p. 8 of the current paper).
Generating adaptation of the model until the data “fit”.
The authors refer to an “autoregressive SEM.” a) What is the autoregressive component in their model? b) Why is including this component important for causal interpretation over time?
Solution
The autoregressive component is social media political persuasion at W1 predicting social media political persuasion at W2 (the autoregressive term).
Including it controls for prior levels of the outcome, so the paths from W1 predictors to W2 persuasion represent change over time, not just cross-sectional association. That makes the causal interpretation (within the limits of observational panel data) much stronger.
In Figure 1’s note the authors say: “The model controls for all variables included in Table 4… and the autoregressive term… by residualizing all observed variables prior to model fitting.”. a) What does “residualizing all observed variables prior to model fitting” mean in practice? b) Why might they choose this strategy instead of explicitly drawing all control paths in the SEM diagram?
Solution
“Residualizing all observed variables prior to model fitting” means they first regress each focal variable on the controls (and the autoregressive term) and then use the residuals (control-adjusted parts) in the SEM.
This avoids an extremely cluttered SEM diagram with dozens of control paths. They model the relations among the remaining, control-adjusted portions of the variables.
12.18 Time to practice on your own
You can download the PDF of the exercises here:
12.18.1 SEM with multiple latent variables
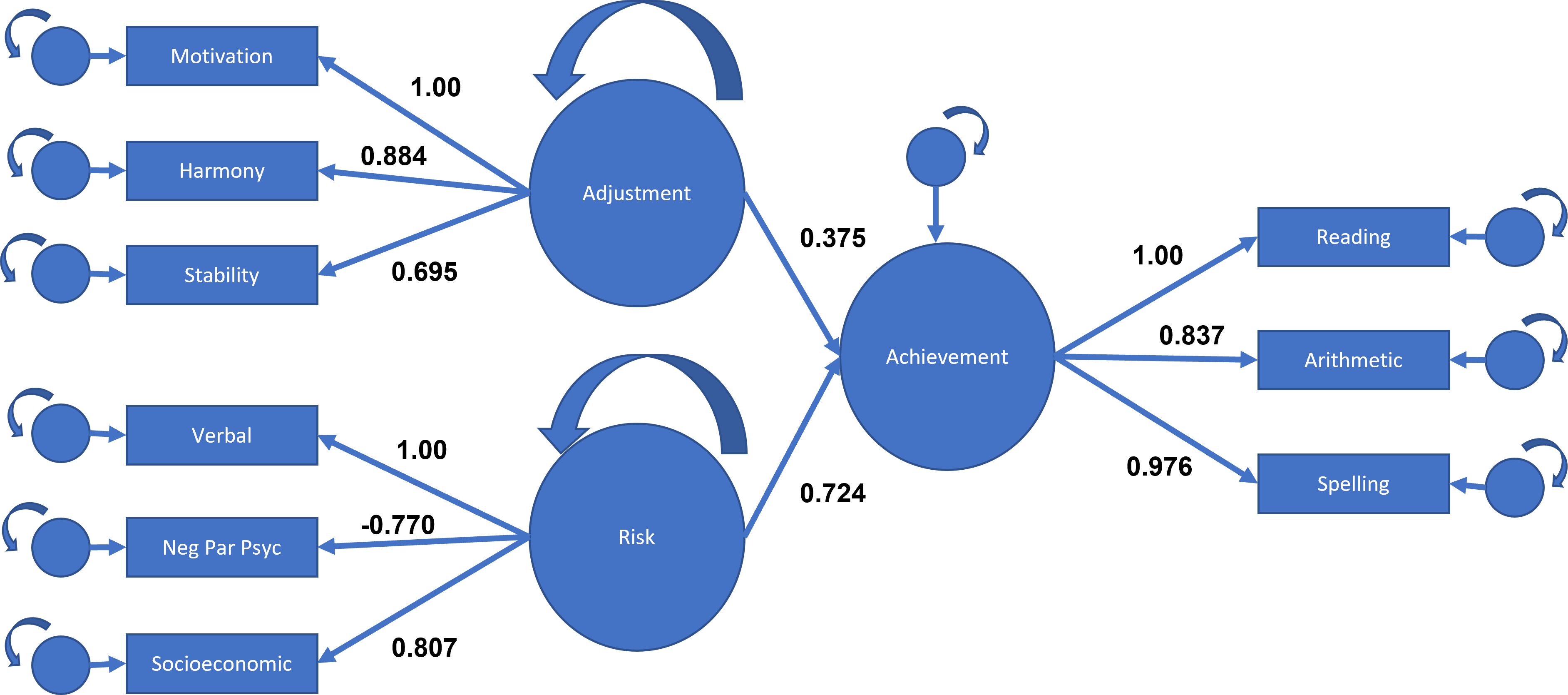
We want to create a structural model that relates multiple latent variables using social science data describing the effect of student background on academic achievement.
We create a measurement model by defining each latent variable:
Adjustment: measured by motivation, harmony, and stability.
Risk: measured by verbal, negative parent psychology, and socioeconomic status.
Achievement: measured by reading, arithmetic, and spelling.
We also define the regression path where achievement will be the combination of adjustment and risk.
Next, we fit the model to the data using sem() from lavaan. Followed by a summary, including model fit.
Show the code
fit <- lavaan::sem(mod, data=dat)summary(fit, fit.measures=TRUE)## lavaan 0.6-19 ended normally after 130 iterations## ## Estimator ML## Optimization method NLMINB## Number of model parameters 21## ## Number of observations 500## ## Model Test User Model:## ## Test statistic 148.982## Degrees of freedom 24## P-value (Chi-square) 0.000## ## Model Test Baseline Model:## ## Test statistic 2597.972## Degrees of freedom 36## P-value 0.000## ## User Model versus Baseline Model:## ## Comparative Fit Index (CFI) 0.951## Tucker-Lewis Index (TLI) 0.927## ## Loglikelihood and Information Criteria:## ## Loglikelihood user model (H0) -15517.857## Loglikelihood unrestricted model (H1) -15443.366## ## Akaike (AIC) 31077.713## Bayesian (BIC) 31166.220## Sample-size adjusted Bayesian (SABIC) 31099.565## ## Root Mean Square Error of Approximation:## ## RMSEA 0.102## 90 Percent confidence interval - lower 0.087## 90 Percent confidence interval - upper 0.118## P-value H_0: RMSEA <= 0.050 0.000## P-value H_0: RMSEA >= 0.080 0.990## ## Standardized Root Mean Square Residual:## ## SRMR 0.041## ## Parameter Estimates:## ## Standard errors Standard## Information Expected## Information saturated (h1) model Structured## ## Latent Variables:## Estimate Std.Err z-value P(>|z|)## adjust =~ ## motiv 1.000 ## harm 0.884 0.041 21.774 0.000## stabi 0.695 0.043 15.987 0.000## risk =~ ## verbal 1.000 ## ppsych -0.770 0.075 -10.223 0.000## ses 0.807 0.076 10.607 0.000## achieve =~ ## read 1.000 ## arith 0.837 0.034 24.437 0.000## spell 0.976 0.028 34.338 0.000## ## Regressions:## Estimate Std.Err z-value P(>|z|)## achieve ~ ## adjust 0.375 0.046 8.085 0.000## risk 0.724 0.078 9.253 0.000## ## Covariances:## Estimate Std.Err z-value P(>|z|)## adjust ~~ ## risk 32.098 4.320 7.431 0.000## ## Variances:## Estimate Std.Err z-value P(>|z|)## .motiv 12.870 2.852 4.512 0.000## .harm 31.805 2.973 10.698 0.000## .stabi 57.836 3.990 14.494 0.000## .verbal 46.239 4.788 9.658 0.000## .ppsych 68.033 5.068 13.425 0.000## .ses 64.916 4.975 13.048 0.000## .read 11.372 1.608 7.074 0.000## .arith 37.818 2.680 14.109 0.000## .spell 15.560 1.699 9.160 0.000## adjust 86.930 6.830 12.727 0.000## risk 53.561 6.757 7.927 0.000## .achieve 30.685 3.449 8.896 0.000
How would you illustrate this analysis using a path diagram?
Solution
To interpret the path diagram, you can: (a) explain what each latent variable represents, (b) describe the key loadings (which indicators load strongly on which factors), (c) explain the structural paths (e.g., adjust → achieve, risk → achieve), and (d) summarize what the model means conceptually.
Concerning the model fit, we have the following indications: CFI = .95 → good, TLI = .93 → acceptable, RMSEA = .102 → poor fit, SRMR = .041 → good. So, overall: mixed fit; model could be improved.
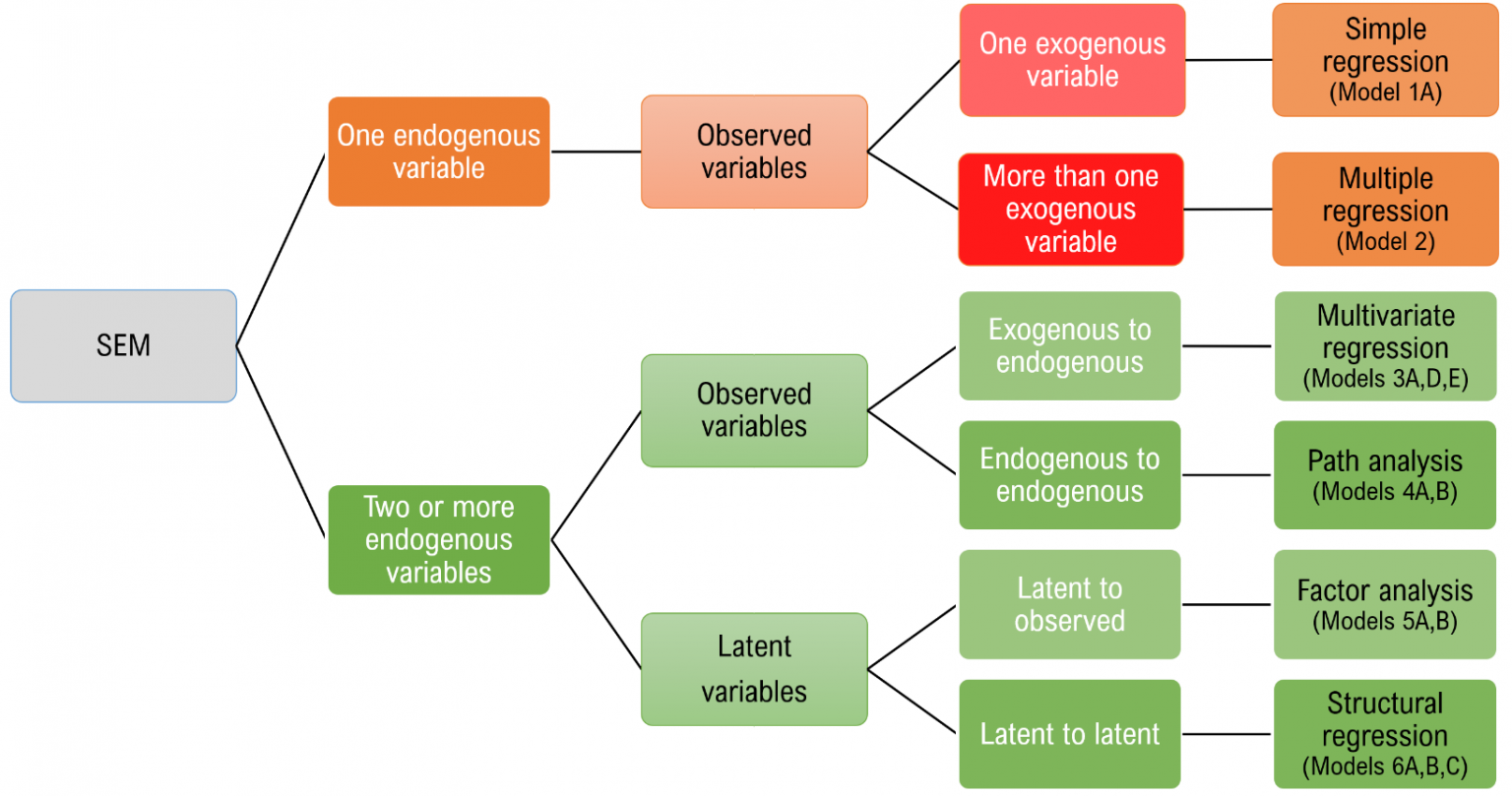
Based on the following flowchart (original can be found here), state whether the following statements are true or false:
SEM encompasses a broad range of linear models and combines simultaneous linear equations with latent variable modeling.
Solution
True: Multivariate regression and path analysis are simultaneous equations of observed variables; factor analysis is a latent variable model, and structural regression combines the concepts of path analysis with factor analysis.
Multivariate regression means that there is always more than one exogenous predictor in my model.
Solution
False: Multivariate regression indicates more than one endogenous variable. You can certainly have only one exogenous predictor of multiple endogenous variables.
Structural regression models the regression paths only among latent variables.
Solution
True: Structural regression defines relationships between latent variables and path analysis defines relationships between observed variables.