CFA is a model-data fit test based on multivariate regression. Outputs are coefficients of paths and fit indices. If the paths are significant and indices indicate acceptable or high degree of fit, that means the structural model is confirmed by data.
10.1.1 Reminder: latent constructs
Latent constructs are not “directly” measurable (e.g. media usage motives, media or brand ratings, attitudes, emotions and empathy in the media reception, trust, etc.).
Furthermore, definitions can be understood differently or terms are completely unknown. Some concepts also have several dimensions/facets, so that one question alone is not enough to fully understand the concept.
Therefore, we should ensure several “indicator variables” that allow conclusions to be drawn about the latent variable.
10.1.2 Reminder: fundamental theorem
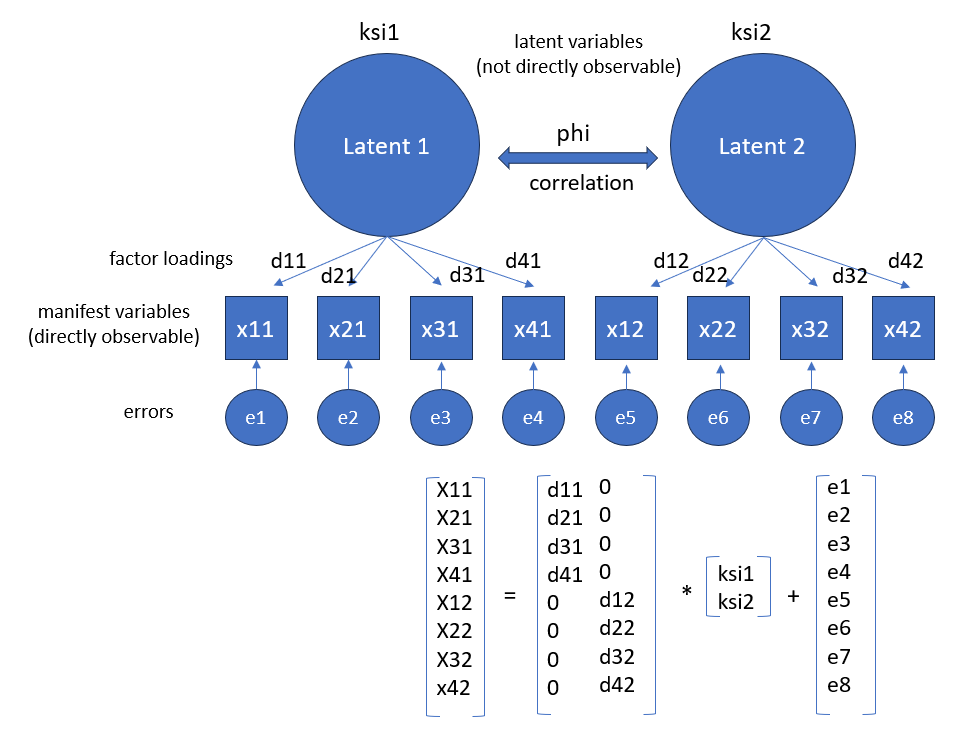
Like the EFA, the CFA is also based on the fundamental theorem of factor analysis:
\(x_{ij}\) = value of person i on observed variable j
\(a_{j1}\) factor loading = correlation of a variable j and factor 1
\(f_{i1}\) = factor value of person i on factor 1
Based on a given (hypothesized) relationship structure between indicator variables and factors (i.e. whether a correlation is assumed or not), to estimate the factor loadings in such a way that the empirical value covariance structure between items can be reproduced as well as possible with their help.
It is about a comparison (better: an adjustment) between empirically found correlations between indicators and the theoretically assumed correlations between factors and items.
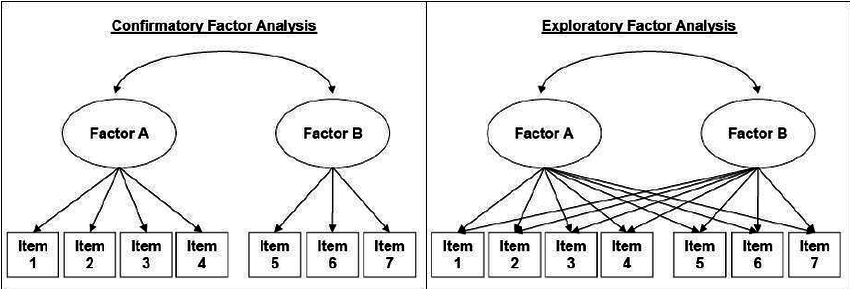
10.1.3 Recap: EFA versus CFA
In EFA:
the number of factors is searched for exploratively with the help of more or less fixed criteria (Kaiser criterion, scree plot, content plausibility).
the assignment of the indicators to the construct is exploratory (via the factor loadings and the rotation).
all variables load on all factors
In CFA:
the number of factors is determined a priori.
the indicators are assigned to the construct on the basis of theoretical considerations.
all aspects of the factor model must be specified in advance: number of factors, relationship patterns between items and factors and between factors, etc.
Thus, CFA is one of the structure-testing methods of multivariate data analysis. Its central goal is testing of measurement models for hypothetical construct.
10.1.4 Concrete research applications
CFA enables us to tackle research questions such as:
Is the assumed factor structure confirmed?
Does my theoretically specified measurement model match my data?
Is there a good fit between the theoretical model and the empirical model?
What is the quality of “competing” measurement models?
Do my data confirm the assumed dimensionality of my construct?
Do my data confirm the assumed hierarchy of my construct?
Can I use the same measuring instrument in different groups (e.g. countries)?
Etc…
10.2 Requirements of CFA
Mathematical requirements:
There are several interval-scaled characteristics (items), each of which is (roughly) normally distributed.
Items that should theoretically load on a factor should correlate empirically (if not, they are probably not determined by the same factor)
Sufficient directly measured variables (items) must be available in order to be able to test the assumed model structure made up of items and factors (model identification, more on this later)
Theoretical assumptions:
Theoretical or at least “logical” justification for the previously expected model structure made up of items and factors
Reflective measurement model
Recommendation: It is best to have an EFA before the CFA - either with a sub-sample of the same dataset or with a different sample.
To this end, the theoretical/latent construct is first precisely defined: describe exactly which aspects a theoretical term contains. Then indicators for the latent construct are developed (item formulation). These should depict the theoretical construct (or its individual dimensions) as precisely as possible. Indicators themselves should correlate with one another, since they depend on the same hypothetical construct (reflective models!).
10.3 Model structure
The problem of identifying models describes the question of whether a system of equations can be solved mathematically. The model parameters (free parameters) must be estimated from the empirical variances and covariances of the manifest variables.
Accordingly, all parameters to be estimated in the model (factor loadings, error terms and, if applicable, permitted correlations between latent variables) must be calculable/representable with the help of empirical parameters.
If this is the case, then the model is identified. If this is not the case, there is (so to speak) an equation with too many unknowns. Such an equation is “unsolvable”, or such a model is “unidentified”. It is about determining the degrees of freedom of the model.
The identification of the model structure consists of two “tasks”:
defining a metric for the latent constructs
checking whether there is enough information to estimate the model
Both steps influence the number of degrees of freedom of the model. This aspect also relates to the complexity of the model. The more complex a model is, the more parameters have to be estimated, and the greater the model’s degrees of freedom must be in order to make the estimation possible.
Nota bene: In general, the degrees of freedom can be defined as the number of independent choices devided by the parameters you have within a system (of equations).
Degrees of freedom
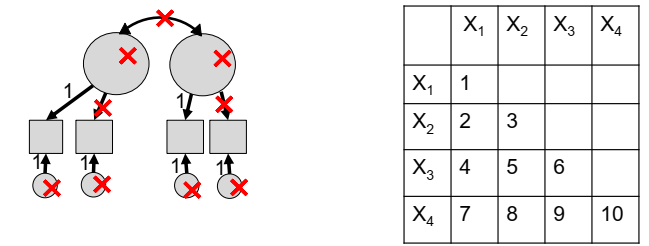
10.4 Identification of a three-item one-factor CFA
Identification for the one-factor CFA with three items is necessary. The total parameters include 3 factor loadings, 3 residual variances and 1 factor variance (which comes from the fact that we do not observe the factor but are estimating its variance).
In order to identify a factor in a CFA model with three or more items, there are two options known respectively as the marker method and the variance standardization method:
marker method fixes the first loading of each factor to 1, where the model-implied covariance matrix is as follows:
variance standardization method fixes the variance of each factor to 1 but freely estimates all loadings, where the model-implied covariance matrix is as follows:
Notice in both models that the residual covariances stay freely estimated.
By fixing \(\lambda_1 = 1\) and by setting the unique residual covariances to zero (e.g. \(\theta_{12}=\theta_{21}=\theta_{13}=\theta_{31}=\theta_{23}=\theta_{32}=0\)), we can demonstrate that we obtain a just-identified model. Indeed, we start with 10 total (unique) parameters, but we fix 1 loading, and 3 unique residual covariances (resulting in 4 fixed parameters). Furthermore, the number of known values is \((3(3+1))/2=6\). Thus, the number of free parameters is 10-4=6. Since we have 6 known values, our degrees of freedom is 6-6=0, which is defined to be saturated. This is known as the marker method.
Similarly, we can go through the process of calculating the degrees of freedom for the variance standardization method. We also start with 10 total (unique) parameters, but we fix 1 factor variance, and 3 unique residual covariances (resulting in 4 fixed parameters). Furthermore, the number of known values is \((3(3+1))/2=6\). Thus, the number of free parameters is 10-4=6. Since we have 6 known values, our degrees of freedom is 6-6=0, which is defined to be saturated.
Degree of freedom: calculation
The formula for calculation degrees of freedom is as follows:
\[ df = \frac{m(m+1)}{2} - 2m - \frac{X(X-1)}{2} \] where \(m\) represent the number of indicators and \(X\) the number of independent latent constructs. We can differentiate between different parts:
\(\frac{m(m+1)}{2}\) gives us the maximum degree of freedom in the model
\(2m\) specifies the number of parameters to be estimated
\(\frac{X(X-1)}{2}\) represents the free off-diagonal covariances of the constructs
In the above example, we have 8 indicators (\(m\)) and 2 latent constructs (\(X\)). Applying the formula, we obtain:
Parameters that are assigned a specific constant value a priori.
Mostly when it is assumed on the basis of theoretical considerations that there are no causal relationships between certain variables, the corresponding parameters are set to zero
However, a value greater than zero can also be specified, to which a parameter is then fixed, for example if the exact stronger of a relationship between two variables is already known in advance
Constrained parameters:
Parameters that should be estimated in the model, but whose value should correspond exactly to the value of one or more other parameters.
E.g. if the influence of two independent variables on a dependent variable is considered to be equal.
If two parameters are defined as restricted, only one parameter has to be estimated instead of two.
Free parameters:
All other parameters whose values are considered unknown and should be estimated from the empirical data.
10.6 Defining a metric for the latent constructs
The latent variables and error variables to be estimated initially have no metric. In order to be able to interpret the variable later, a scale must be assigned.
To do so, you can choose a reference variable and fix the factor loading to 1. With regard to the latent variable, the best indicator variable should be selected. It then means that the latent variable is identical to the selected indicator variable except for the measurement error. In addition, all relationships between the measurement error terms to be estimated and the measured indicator variables are fixed at 1. It then means that the measurement errors to be estimated correspond to the observed values, except for the influence of the latent variables.
10.7 Checking whether there is enough information to estimate the model
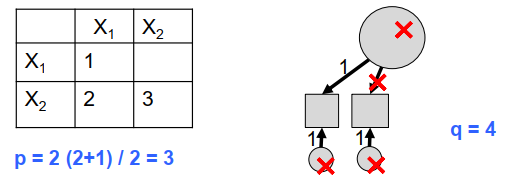
If n manifest variables are collected within the framework of a project, then the empirical variances and covariances of these variables can be calculated:
\[ p = \frac{n(n+1)}{2} \]
where p corresponds to the number of non-redundant values in the variance-covariance matrix (it thus corresponds to the available “information” that we use as the basis for calculating all free parameters of our model).
The difference between the available empirical information (p) and the number of (free) parameters to be estimated (q) gives the degrees of freedom of the model (\(df_M\)):
\[ df_M = p - q \]
where p is the number of empirical information available from the n empirical indicators) and q corresponds to the number of free parameters to be estimated in each case.
If the empirically available information is the same as the number of parameters to be estimated, the number of model degrees of freedom corresponds to zero. The number of model parameters to be estimated must not exceed the number of empirical information given, otherwise a model is not identified (i.e., not solvable). Furthermore, the degrees of freedom of the model must be superior or equal to 0 for a specified model to be identified.
In the following example, the model is under-identified (df < 0): the information available from the empirical data is not sufficient to calculate the parameters.
What about the next example?
Is the model under- or over-identified?
A positive number of degrees of freedom is necessary for the solvability of SEM/CFA! For empirical surveys, ensure that at least as many indicator variables are surveyed as are necessary to achieve a positive number of degrees of freedom. In the example above:
The CFA first calculates the empirical variance-covariance matrix (in short: covariance matrix) with the collected data (= empirical relationships in the data). Based on the defined measurement model, the model-theoretical covariance matrix is calculated (= expected relationships in the data).
The covariance matrix should be reproduced as accurately as possible by the model. This means that the model-theoretical covariance matrix should resemble the empirical covariance matrix as closely as possible.
The better it is possible to reproduce the empirical covariance matrix with the model-theoretical covariance matrix, the more reliable the parameter estimates are and the better the model is.
To assess the model quality so-called fit-indices/fit-measures describe how good the model is.
Exactly one solution is possible for exactly identified models, several solutions are possible for over-identified models, the best solution must be found. The solution is improved with each (iterative) step by improving the fit of the model (i.e. the fit of the model to the empirical data/the empirical covariance matrix). In other words, the difference between the empirical and model-theoretical covariance matrix should be minimal.
The parameters can actually be estimated using various functions. The most common method is the so-called Maximum Likelihood (ML) method. Here the estimated parameter is selected that is most likely to reproduce the observed data. This method assumes metric data.
10.9 Checking the quality
Once a solution has been found, it must be checked for quality. The reliability and validity of the measurement must therefore be assessed.
Reliability: Repeated measurements must always produce the same result (items must all show a high loading with the latent construct)
Validity: the measuring instrument should measure what it is supposed to measure
The assessment of the results follows a multi-stage process:
Checking at indicator level
Construct level testing
Examination on model level
Concerning the examination at indicator level (items), we must ensure that only “good” indicators are included in a model. Thus, there should be sufficiently high correlations between the items (e.g. EFA, Cronbach’s Alpha, etc). Furthermore, the plausibility of the factor loadings, the significance of the factor loadings, and the strength of the factor loadings (and of the squared factor loadings) should be determined.
Standardized solution corresponds to factor loadings (to be interpreted as in EFA, values >.5 are desirable)
Squared factor loadings indicate the percent variance of a variable that is explained by the factor behind it (should reach at least .3)
At the construct level (factors), the question is answered as to whether the constructs/factors are reliably and validly measured (e.g. factor reliability, average extracted variance of the factors, and discriminant validity).
Factor reliability (should be > .5)
Average extracted variance of factors (DEV, should be > .5)
Discriminant validity (Fornell/Larcker criterion)
DEV > squared correlation of the constructs (=common variance of the factors)
Measure for the fact that the explanation of the variance of the factors on the indicators is greater than the connection between the factors
The examination at model level (overall model) suggests to check whether the empirical variance-covariance matrix is reproduced as well as possible by the model-theoretical variance-covariance matrix (e.g. Fit-indices, Chi-Square test statistic, RMSEA and SRMR).
Chi-Square Test (H0: empirical covariance matrix = model-theoretical covariance matrix)
The smaller the difference between the two matrices, the smaller the chi-square value (the smaller the chi-square, the better).
The test should not turn out to be significant, since equality between the empirical and model-theoretical variance-covariance matrix is desirable.
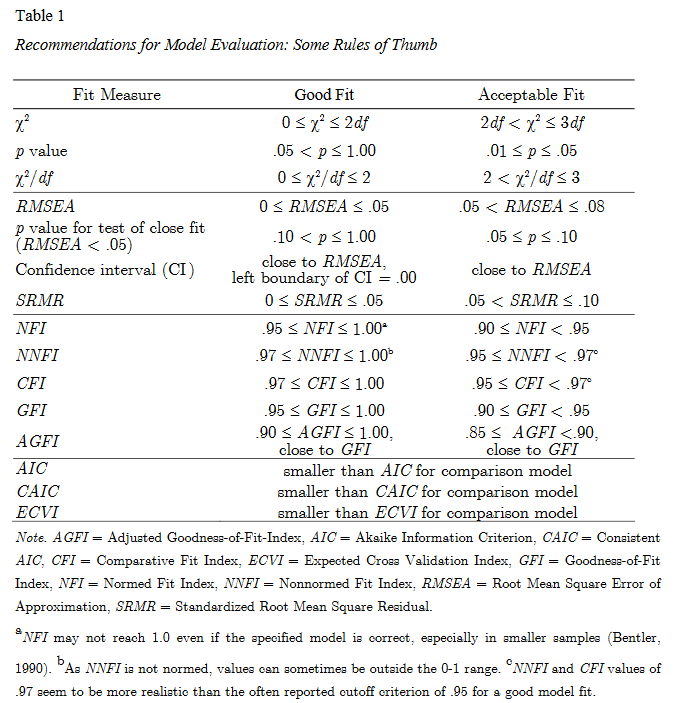
Recommendations for model model evaluation
The original table from Schermelleh-Engel et al. (2003) can be found here.
10.10 Model Chi-square
The model chi-square is defined as either \(nF_{ML}\) or \((n-1)F_{ML}\) depending on the statistical package where \(n\) is the sample size and \(F_{ML}\) is the fit function from maximum likelihood.
The model chi-square is a meaningful test only when you have an over-identified model (there are still degrees of freedom left over after accounting for all the free parameters in your model).
Note on the sample size
Model chi-square is sensitive to large sample sizes. So how big of a sample do we need? Kline (2016) notes the \(N:q\) rule, which states that the sample size should be determined by the number of \(q\) parameters in your model, and the recommended ratio is \(20:1\). This means that if you have 10 parameters, you should have n=200.
Reference: Kline, R. B. (2016). Principles and Practice of Structural Equation Modelling, 4th edn. New York. NY: The Guilford Press.
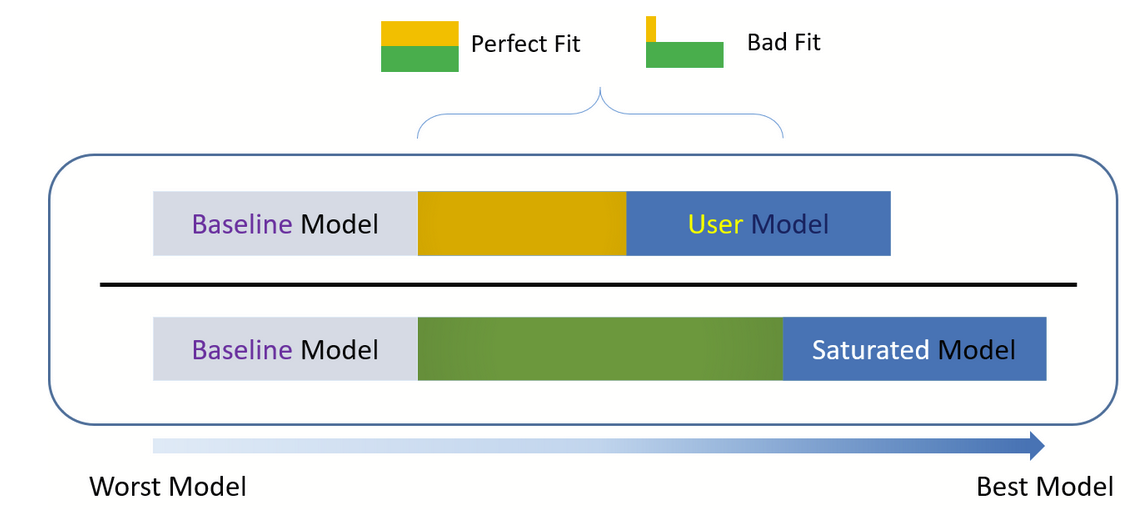
10.11 Baseline model
The model test baseline is also known as the null model, where all covariances are set to zero and freely estimates variances. Rather than estimate the factor loadings, we only estimate the observed means and variances (removing all the covariances). Recall that we have \(\frac{p(p+1)}{2}\) covariances. Since we are only estimating the \(p\) variances we have \(\frac{p(p+1)}{2}-p\) degrees of freedom. You can think of the baseline (or null) model as the worst model you can come up with and the saturated model as the best model. Theoretically, the baseline model is useful for understanding how other fit indices are calculated.
10.12 Approximate fit indexes
To resolve the problem related to the Chi-square sensitivity under large samples, approximate fit indexes that are not based on accepting or rejecting the null hypothesis were developed. These approximate fit indexes can be classified into:
incremental or relative fit indexes (e.g. CFI and TLI): assesses the ratio of the deviation of the user model from the baseline model against the deviation of the saturated model (best fitting model) from the baseline model
absolute fit indexes (e.g. RMSEA): compares the user model to the observed data
10.12.1 CFI and TLI
The CFI or comparative fit index is a popular fit index as a supplement to the model chi-square. Let \(\delta = \chi^2-df\) where \(df\) is the degrees of freedom for that particular model. The closer \(\delta\) is to zero, the more the model fits the data. The formula for the CFI is:
TLI is also an incremental fit index. The term used in the TFI is the relative chi-square (a.k.a. normed chi-square) defined as \(\chi^2/df\). Compared to the model chi-square, relative chi-square is less sensitive to sample size. Whereas \(\chi^2/df=1\) indicates perfect fit, some researchers say that a relative chi-square greater than 2 indicates poor fit. The TLI is defined as:
Suppose you ran a CFA with 20 degrees of freedom. What would be the acceptable range of chi-square values based on the criteria that the relative chi-square greater than 2 indicates poor fit?
The range of acceptable chi-square values ranges between 20 (indicating perfect fit) and 40, since 40/20 = 2.
10.12.2 RMSEA
RMSEA (Root Mean Squared Error of Approximation):
This measure uses inferential statistics to check whether a model can approximate reality well (= approximation test).
It is therefore not about the absolute correctness of the model, as with the Chi-Square test, but about evaluating the best possible approximation.
Usually there is a discrepancy between the empirical and model-theoretical covariance matrix. Therefore, descriptive measures of discrepancy are often used.
These give an answer to the question of whether an existing discrepancy can be neglected and also includes the model complexity.
If the empirical and model-theoretical covariance matrix are completely identical, this measure assumes a value of zero.
Recommendations:
SRMR ≤ .05 good fit
SRMR ≤ .10 more acceptable
10.13 In case of bad model fit
There are several things we can do if the model fit is too bad:
View Modification indices (MI) and adjust model if necessary
MI indicate how the model fit can be improved (e.g. how the theoretical model can better approximate the empirical data)
MI usually propose to release certain fixed parameters
Many MI proposals do not necessarily make sense with regard to the theoretical assumptions (find a balance between mathematical fit and theoretical meaning)
10.14 Comparison of different models
Comparing different models can be useful when we have competing theoretical models.
Comparison rules:
lower RMSEA = descriptively better model
lower SRMR = descriptively better model
larger CFI = descriptively better model
smaller AIC = descriptively better model
Statistically verified comparisons between competing models only possible with nested models (= models are exactly identical except that one path is more/less estimated).
To do so, we can rely on the Chi-Square Difference Test. If the test is not significant, then the model with more fixed parameters (i.e. the more economical and therefore theoretically clearer model) is no worse than the model in which more paths are allowed. Beware that, like the chi-square test, the chi-square difference test is also very fast significant.
10.15 In a nutshell
In CFA, a previously accepted measurement model (number of factors, assignment of indicators to factors, etc.) is checked on the basis of collected data.
The mathematical specification of measurement models works with fixed and free parameters. Path diagrams can be converted into systems of equations.
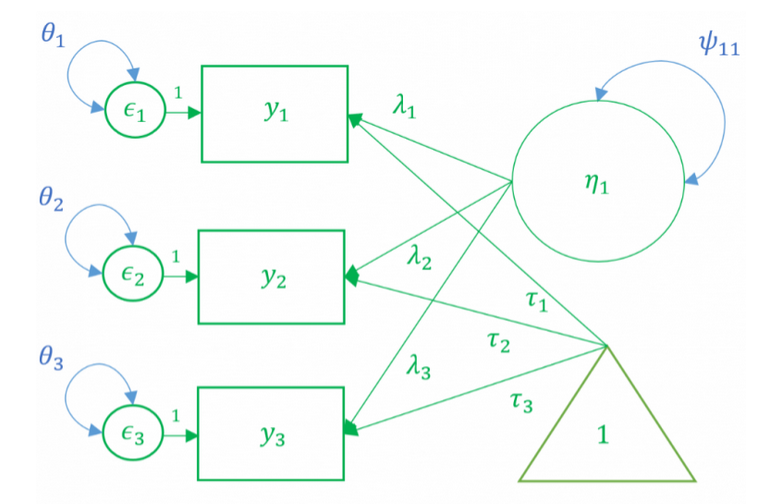
The factor analysis or measurement model is essentially a linear regression model where the main predictor, the factor, is latent. For a single subject, the simple linear regression equation is defined as: \(y = b_0 + b_1x + e\). Similarly, for a single item, the factor analysis model is: \(y_1 = \tau_1 + \lambda_1\eta + e\). We can represent this multivariate model (i.e., multiple outcomes, items, or indicators) as a matrix equation:
The variance-covariance matrix can be described using the model-implied covariance matrix. This is in contrast to the observed population covariance matrix which comes only from the data.
The basic assumption of factor analysis is that for a collection of observed variables there are a set of underlying factors that can explain the interrelationships among those variables. These interrelationships are measured by the covariances.
Traditionally, the intercepts (\(\tau\)) are not estimated, which means that all the parameters we need can come directly from the covariance model.
In the model-implied covariance, we assume that the residuals are independent which means that for example, the covariance between the second and first residual (\(\theta{23}\)), is set to zero. As such the only covariance terms to be estimated are the variance of the latent factors (\(\psi\)) and the variances of the residuals (\(\theta{11}\), \(\theta{22}\) and \(\theta{33}\)).
Models must have sufficient degrees of freedom (relationship between empirical information and parameters to be estimated) in order to be mathematically solvable (model identification).
In order to identify a factor in a CFA model with three or more items, there are two options known respectively as the marker method and the variance standardization method:
marker method fixes the first loading of each factor to 1,
variance standardization method fixes the variance of each factor to 1 but freely estimates all loadings.
In matrix notation, the marker method can be written as:
Indicator level: strength and significance of the factor loadings as well as the size of the squared factor loadings
Construct level: factor reliability, average extracted variance of factors, discriminant validity
Model Level: Chi-Square Test Statistic, RMSEA, SRMR
Four commonly used model fit measures are:
Model chi-square is the chi-square statistic obtained from the maximum likelihood statistic (in lavaan: Test Statistic for the Model Test User Model)
CFI is the Comparative Fit Index – values can range between 0 and 1 (values greater than 0.90, conservatively 0.95 indicate good fit)
TLI Tucker Lewis Index which also ranges between 0 and 1 (if greater than 1 it should be rounded to 1; values greater than 0.90 indicating good fit). The CFI is always greater than the TLI.
RMSEA is the root mean square error of approximation (in lavaan: p-value of close fit, that the RMSEA < 0.05. If rejected, it means that the model is not a close fitting model).
Historically, model chi-square was the only measure of fit but in practice the null hypothesis was often rejected due to the chi-square’s heightened sensitivity under large samples. To resolve this problem, approximate fit indexes that were not based on accepting or rejecting the null hypothesis were developed. These can be further classified into absolute (e.g. CFI and TLI) and incremental (e.g. RMSEA) fit indexes:
incremental fit indexes: assess the ratio of the deviation of the user model from the worst fitting model (a.k.a. the baseline model) against the deviation of the saturated model from the baseline model.
absolute fit indexes: compare the user model to the observed data.
10.16 How it works in R?
See the lecture slides confirmatory factor analysis:
You can also download the PDF of the slides here:
10.17 Quiz
True
False
Statement
Items that should theoretically load on a factor should correlate empirically.
Free parameters are assigned a specific constant value a priori.
In exactly identified models, multiple solutions are possible.
Over-identified models allow for multiple solutions, and the best one is selected.
My results will appear here
10.18 Example from the literature
The following article relies on EFA as a method of analysis:
Schulz, A., Müller, P., Schemer, C., Wirz, D. S., Wettstein, M., & Wirth, W. (2018). Measuring populist attitudes on three dimensions. International Journal of Public Opinion Research, 30(2), 316-326. Available here.
Please reflect on the following questions:
What is the research question of the study?
What are the research hypotheses?
Is CFA an appropriate method of analysis to answer the research question?
What are the main findings of the CFA?
And some more questions from the tutors:
After the previous week’s session on EFA, why is CFA an appropriate method for the paper?
Solution
CFA is appropriate to test strong hypotheses that have been formulated in a prior (EFA) study.
What could be an issue with performing CFA on the same data as the EFA?
Solution
Performing CFA on the same data that was used for EFA undermines the confirmatory nature of CFA. EFA is data-driven: it searches for possible factor structures based on observed correlations. CFA is theory-driven: it tests whether a hypothesized structure fits the data. If you use the same data for both, you are essentially testing the model on the same sample that generated it, which:
Leads to overfitting (the model fits noise or idiosyncrasies of that sample).
Produces inflated goodness-of-fit indices (CFI, TLI, RMSEA, etc.) that do not generalize.
Violates the principle of cross-validation and reduces external validity.
Best practices:
Split your sample (e.g., 50% for EFA, 50% for CFA)
Collect a new dataset for the CFA.
This way, you are testing whether the factor structure found in EFA replicates in fresh data - a key requirement for model validation.
In Table 1, National Sample, which model (I-Factor model “Akkerman”, I-Factor model, or 3-Factor model) is the best?
Solution
Solution: 3-Factor Model, since it has higher CFI, and lower RMSEA & SRMR.
Is the first model they are testing without removing items a good fit for the data?
Solution
It is still acceptable: the Chi-Square is significant (p-value is <0.001) and the RMSEA is 0.06.
10.19 Time to practice on your own
You can download the PDF of the CFA exercises here:
10.19.1 Exercise 1: Big-5
To illustrate CFA, let us use the same International Personality Item Pool data available in the psych package to confirm the big 5 personality structure.
Start by defining the model using the lavaan syntax and extract the parameters.
Show the code
# load the datadata <- psych::bfi[, 1:25] # 25 first columns corresponding to the itemsdata <-na.omit(data)# have a look at the correlation matrix library(ggplot2)library(reshape2)corr <-round(cor(data), 2)melted_corr <-melt(corr)ggplot(melted_corr, aes(Var1, Var2, fill = value)) +geom_tile(color ="white") +scale_fill_gradient2(low ="blue", high ="red", mid ="white",midpoint =0, limit =c(-1,1), space ="Lab",name ="Correlation") +theme_minimal() +theme(axis.text.x =element_text(angle =45, vjust =1, size =10, hjust =1)) +coord_fixed() +geom_text(aes(label = value), color ="black", size =0)# write the modelmodel_measurement <-" Neuroticism =~ N1 + N2 + N3 + N4 + N5 Conscientiousness =~ C1 + C2 + C3 + C4 + C5 Extraversion =~ E1 + E2 + E3 + E4 + E5 Agreeableness =~ A1 + A2 + A3 + A4 + A5 Opennness =~ O1 + O2 + O3 + O4 + O5"fit_measurement <- lavaan::sem(model_measurement, data = data)# summary(fit_measurement, fit.measures = TRUE, standardized = TRUE)coef <- lavaan::parameterestimates(fit_measurement)# output: only 10 first rowslavaan::parameterEstimates(fit_measurement, standardized=TRUE) |> dplyr::select('Latent Factor'=lhs, Indicator=rhs, B=est, SE=se, Z=z, 'p-value'=pvalue, Beta=std.all) |> dplyr::slice_head(n =10) |># select only the 10 first rows knitr::kable(digits =3, booktabs=TRUE)
Latent Factor
Indicator
B
SE
Z
p-value
Beta
Neuroticism
N1
1.000
0.000
NA
NA
0.825
Neuroticism
N2
0.947
0.024
39.899
0
0.803
Neuroticism
N3
0.884
0.025
35.919
0
0.721
Neuroticism
N4
0.692
0.025
27.753
0
0.573
Neuroticism
N5
0.628
0.026
24.027
0
0.503
Conscientiousness
C1
1.000
0.000
NA
NA
0.551
Conscientiousness
C2
1.148
0.057
20.152
0
0.592
Conscientiousness
C3
1.036
0.054
19.172
0
0.546
Conscientiousness
C4
-1.421
0.065
-21.924
0
-0.702
Conscientiousness
C5
-1.489
0.072
-20.694
0
-0.620
Also get the fit statistics of the model. Is it a good model?
The fit statistics provide mixed evidence about the adequacy of the measurement model:
Chi-square test: χ²(265) = 4165.47, p < .001. The highly significant result suggests that the model does not fit the data perfectly. However, with large samples (N = 2436 here), the chi-square test is often overly sensitive and almost always significant.
RMSEA: 0.08. This indicates a mediocre fit (values < 0.05 are considered good, 0.05–0.08 acceptable, and > 0.10 poor). The RMSEA p-value < .001 confirms that the RMSEA is significantly greater than 0.05.
SRMR: 0.08. This is at the upper boundary of acceptable fit (commonly < 0.08).
Overall: While the model is not a perfect fit (significant chi-square, RMSEA at the threshold, SRMR borderline acceptable), the indices suggest that the model provides a reasonable but not excellent fit to the data. Improvements to the specification may be necessary.
Lastly, make a visualization of the output using the semPaths() function.
Show the code
# semPlot::semPaths(fit_measurement, what = "est", rotation = 2, # style = "lisrel", font = 2) # title("Row Estimations")
10.19.2 Exercise 2: Calculate the degree of freedom for one-factor CFA with more than 3 items
The benefit of performing a one-factor CFA with more than three items is that:
your model is automatically identified (there will be more than 6 free parameters)
your model will not be saturated (there will be degrees of freedom left over to assess model fit).
Imagine that we have specified the following model in lavaan with 8 items.
From this model, explain how to obtain 20 degrees of freedom from the 8-item one factor CFA by first calculating the number of free parameters and comparing that to the number of known values. Use the variance standardization method.
Solution
The number of elements in the variance-covariance matrix is:
\[ \frac{n*(n+1)}{2} = \frac{8*(8+1)}{2} = 36 \]
We also have 8 loadings (\(\lambda_i\)), 8 residual variances (\(\theta_i\)) and 1 variance of the factor (\(\psi_i\)). Thus, in total we have 17 unique parameters.
This gives us 17-1=16 free parameters, where we have fixed 1 parameter (using the variance standardization method).
Therefore, the degrees of freedom is 36-16=20. This suggests that we have an over-identified model (degrees of freedom above 0).
10.19.3 Exercise 3: Calculate the degree of freedom for two-factor CFA with more than 3 items
Imagine that we have specified the following model in lavaan with two factors:
Show the code
mod <-' f1 =~ q01 + q03 + q04 + q05 + q08 f2 =~ a*q06 + a*q07 ## equate the 2 items on the same factors ## while setting the factor variance at 1 f1 ~~ 0*f2'## orthogonal factors twofac7items <-cfa(mod, data=dat,std.lv=TRUE) # note: by specifyingstandardized=TRUE we implement the variance standardization methodsummary(twofac7items, fit.measures=TRUE, standardized=TRUE)
The two-item factor presents a special problem for identification, and there are two options to identify a two-item factor:
Freely estimate the loadings of the two items on the same factor but equate them to be equal while setting the variance of the factor at 1.
Freely estimate the variance of the factor, using the marker method for the first item, but covary (correlate) the two-item factor with another factor.
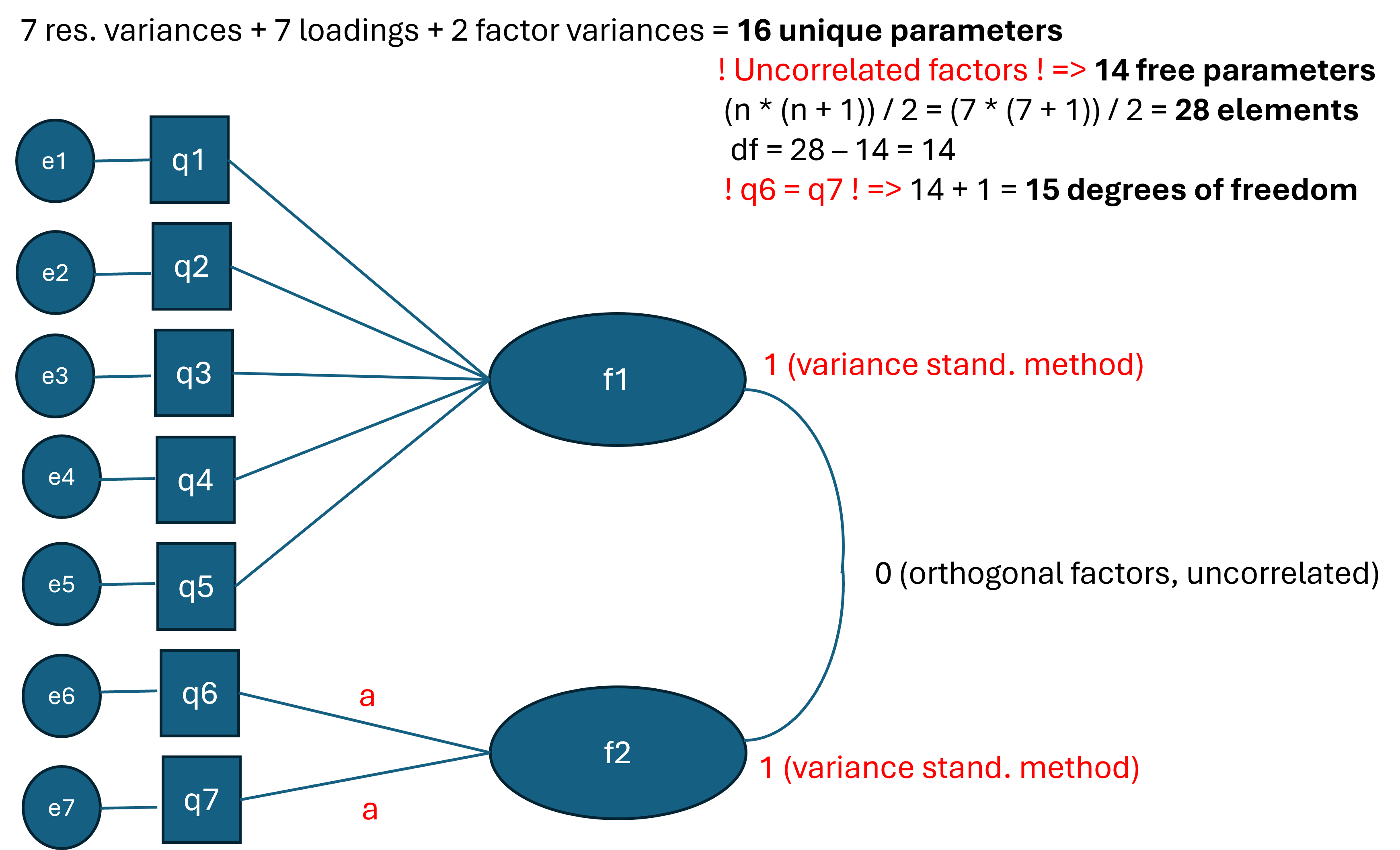
From this model, explain how to obtain 15 degrees of freedom from the 7-item two-factor CFA by first calculating the number of free parameters and comparing that to the number of known values. We also make the assumption of uncorrelated (orthogonal) factors.
Solution
The number of elements in the variance-covariance matrix is:
\[ \frac{n*(n+1)}{2} = \frac{7*(7+1)}{2} = 28 \]
We also have 7 loadings (\(\lambda_i\)), 7 residual variances (\(\theta_i\)) and 2 variance of the factors (\(\psi_i\)). Thus, in total we have 16 unique parameters. But we make the assumption of uncorrelated factors, thus we have 14 free parameters.
Therefore, the degrees of freedom is 28-14=14. However, as we constrained the loadings of q06 and q07 to be equal, it frees up a parameter and thus we have 14+1=15 degrees of freedom.
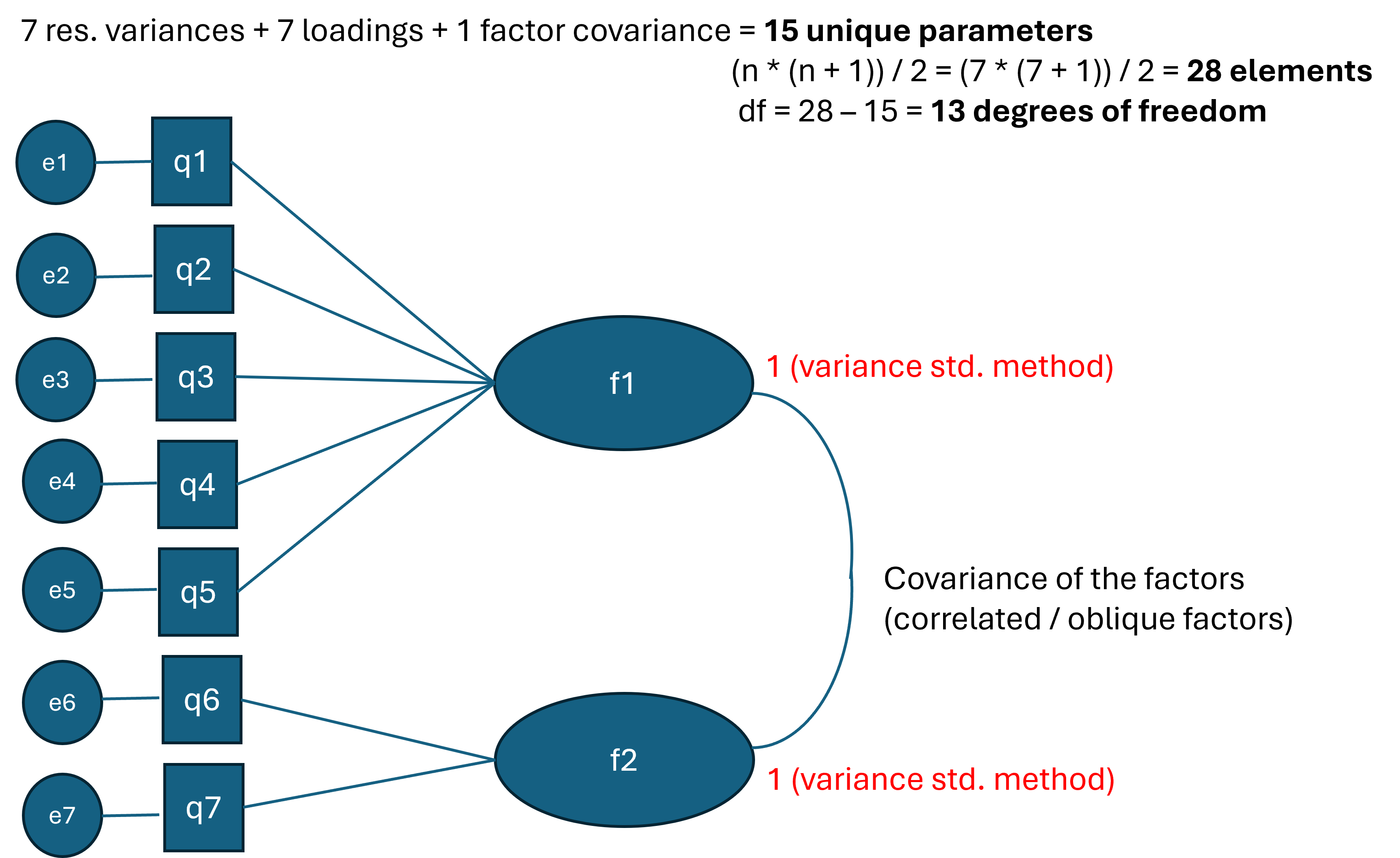
Now, we make the assumption of correlated (oblique) factors, which gives us the following model:
Explain how to obtain 13 degrees of freedom from the 7-item two-factor CFA by first calculating the number of free parameters and comparing that to the number of known values.
Solution
The number of elements in the variance-covariance matrix is:
\[ \frac{n*(n+1)}{2} = \frac{7*(7+1)}{2} = 28 \]
We also have 7 loadings (\(\lambda_i\)), 7 residual variances (\(\theta_i\)) and 1 covariance of the factors (\(\psi_{21}\)). Thus, in total we have 15 unique parameters. Therefore, the degrees of freedom is 28-15=13.